VLink 的 base 基础库提供了一套轻量、高性能的底层工具集,供通信核心与上层应用共同使用。 所有组件均以 C++17 编写,无第三方强制依赖,可独立集成。
相关文档:
11.1 组件总览
11.2 日志系统 Logger
概述
vlink::Logger 是一个全局单例日志器,通过 Logger::init() 初始化,通过宏在任意位置写入日志。 它同时支持控制台 Sink 和文件 Sink,每个 Sink 可独立配置最低日志级别。
日志级别
| 值 | 枚举 | 用途 |
| 0 | kTrace | 详细跟踪,用于排查内部逻辑 |
| 1 | kDebug | 开发调试信息 |
| 2 | kInfo | 正常运行信息 |
| 3 | kWarn | 异常但可恢复的情况 |
| 4 | kError | 可恢复错误 |
| 5 | kFatal | 写日志后抛出 Exception::RuntimeError |
| 6 | kOff | 关闭对应 Sink |
当消息级别 >= kDetailLevel(默认 kWarn)时,宏自动在消息前追加 {filename:line} 定位信息。
四种输出风格
| 风格 | 宏前缀 | 示例 | 说明 |
| 流式(VLOG) | VLOG_I | VLOG_I("x=", x) | 使用 FastStream,零堆分配 |
| 格式化(MLOG) | MLOG_I | MLOG_I("x={}", x) | 使用 VLink format::format_to_n |
| C 风格(CLOG) | CLOG_I | CLOG_I("x=d", x) | 使用 std::snprintf |
| RAII 流(SLOG) | SLOG_I | SLOG_I << "x=" << x | WrapperStream 析构时自动提交 |
每种风格对应六个级别的短宏(_T/_D/_I/_W/_E/_F)。每条消息最大 4096 字节(kLocalBufferSize),超出将被截断。
编译期过滤
#define VLINK_LOG_LEVEL 2
#define VLINK_LOG_DETAIL_LEVEL 3
#define VLINK_LOG_DISABLE_SHORT
自定义后端
my_console_output(level, msg);
});
my_file_output(level, msg);
});
static void register_file_handler(Callback &&callback) noexcept
Registers a custom handler for file log output.
static void register_console_handler(Callback &&callback) noexcept
Registers a custom handler for console log output.
Level
Severity level for log messages.
Definition logger.h:148
回溯环形缓冲区
static void dump_backtrace() noexcept
Flushes the backtrace ring buffer to the active sinks.
static void enable_backtrace(size_t size) noexcept
Enables a ring-buffer backtrace of the last size log messages.
static void disable_backtrace() noexcept
Disables backtrace collection and clears the ring buffer.
完整使用示例
int main() {
int node_id = 42;
double temp = 78.5;
VLOG_I(
"node started, id=", node_id);
MLOG_W(
"temperature is {} C, threshold exceeded", temp);
CLOG_E(
"errno=%d msg=%s", errno, strerror(errno));
SLOG_D <<
"values: " << node_id <<
" temp=" << temp;
try {
VLOG_F(
"unrecoverable condition: ",
"disk full");
} catch (const std::exception& e) {
}
return 0;
}
static void set_file_level(Level level) noexcept
Sets the minimum level for the file sink.
static void set_console_level(Level level) noexcept
Sets the minimum level for the console sink.
@ kInfo
Definition logger.h:151
@ kDebug
Definition logger.h:150
static void init(const std::string &app_name="", const std::string &log_path="") noexcept
Initialises the logger singleton.
Global singleton logger with three output styles and pluggable backends.
#define CLOG_E(...)
Definition logger.h:866
#define VLOG_F(...)
Definition logger.h:856
#define SLOG_D
Definition logger.h:884
#define VLOG_I(...)
Definition logger.h:850
#define MLOG_W(...)
Definition logger.h:876
11.3 字节缓冲区 Bytes
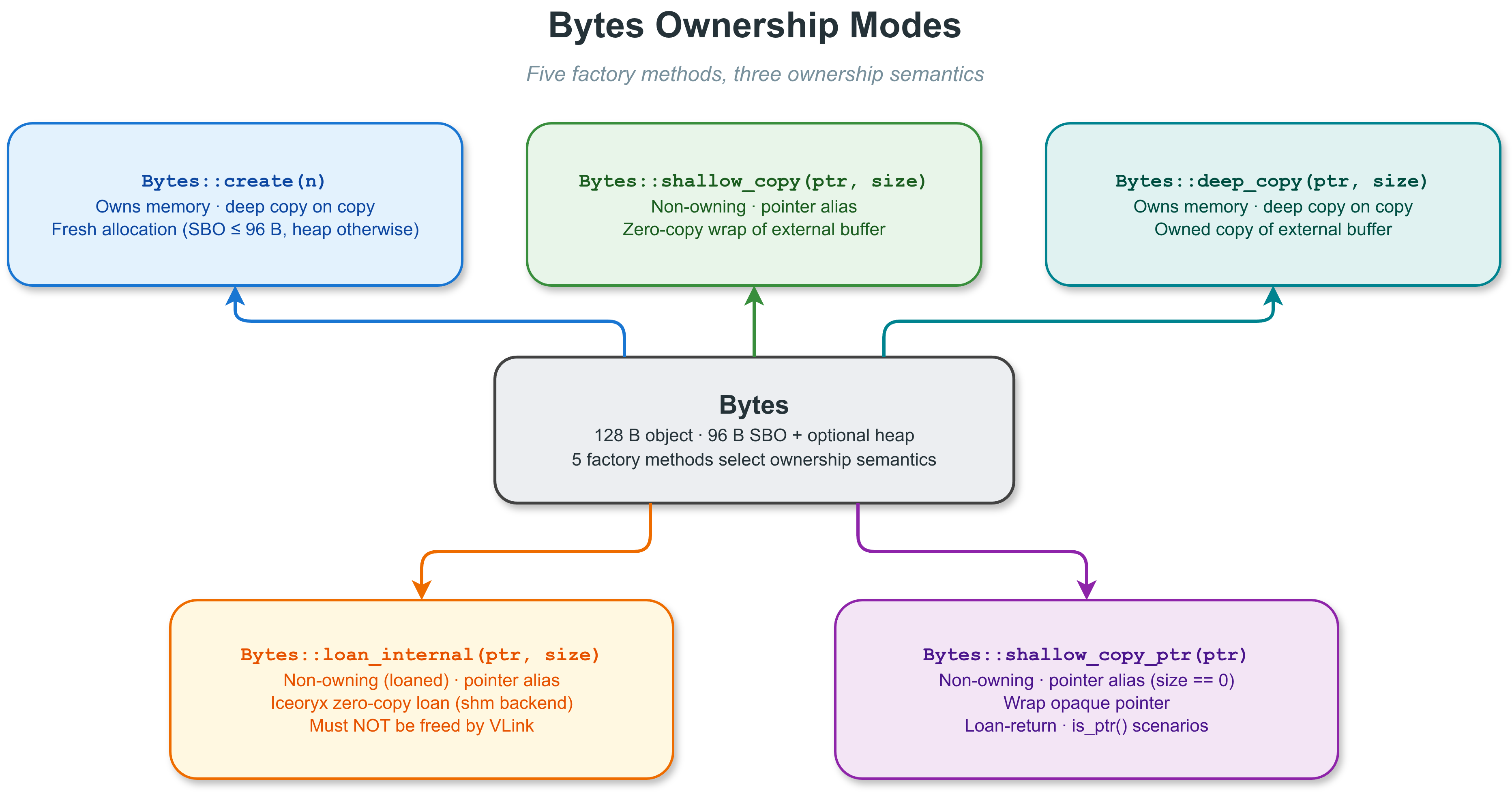
Bytes 五种所有权模式
概述
vlink::Bytes 是 VLink 的核心数据载体,总大小固定为 **128 字节**。 96 字节以内的数据直接存储在对象内部(小缓冲优化 SBO),无需堆分配。 超出部分从内存池或系统堆分配。
所有权模型
| 创建方式 | 拥有内存 | 复制行为 | 典型用途 |
| Bytes::create(n) | 是 | 深拷贝 | 新建分配 |
| Bytes::shallow_copy() | 否 | 指针别名 | 零拷贝包装外部缓冲区 |
| Bytes::deep_copy() | 是 | 深拷贝 | 拥有外部数据的副本 |
| Bytes::loan_internal() | 否(借用) | 指针别名 | Iceoryx 零拷贝借用(shm 后端) |
| Bytes::shallow_copy_ptr() | 否 | 指针别名 | 包装不透明指针(size == 0) |
内存布局
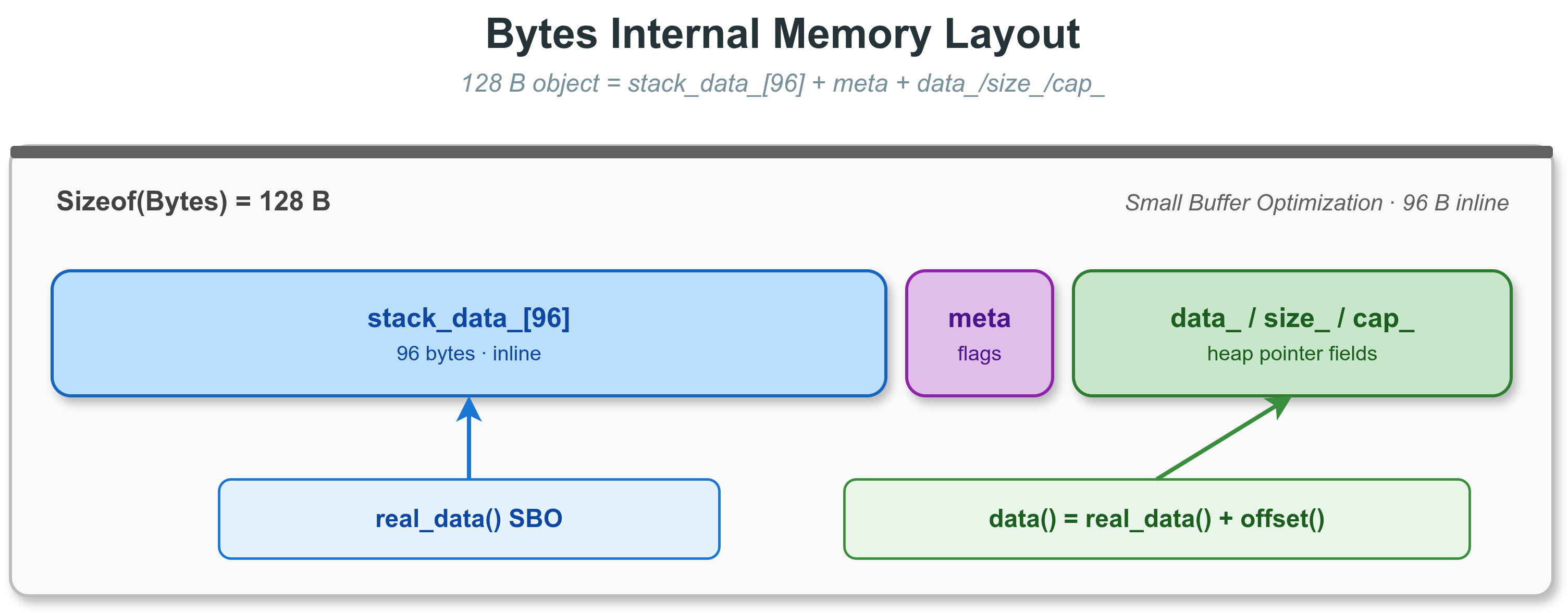
Bytes 内存布局
offset 字段为协议头预留前缀区域,data() = real_data() + offset()。
常用操作
std::memcpy(buf.data(), payload, 64);
size_t n = buf.size();
bool is_owner = buf.is_owner();
bool is_empty = buf.empty();
for (uint8_t byte : buf) {
process(byte);
}
std::string s = buf.to_string();
std::string_view sv = buf.to_string_view();
std::vector<uint8_t> v = buf.to_raw_data();
buf.resize(128);
buf.shrink_to(32);
buf.clear();
Versatile byte buffer with small-buffer optimisation, ownership semantics and compression.
Versatile 128-byte byte buffer with SBO, five ownership modes and compression helpers.
Definition bytes.h:113
static Bytes shallow_copy(uint8_t *data, size_t size) noexcept
Creates a non-owning Bytes alias pointing to an external mutable buffer.
static Bytes from_string(const std::string &str, uint8_t offset=0) noexcept
Constructs a Bytes buffer from a std::string by deep-copying its contents.
uint8_t * data() noexcept
Returns a pointer to the start of the user data region (after the prefix offset).
Definition bytes.h:860
static Bytes create(size_t size, uint8_t offset=0) noexcept
Creates an owned Bytes buffer of the given size.
static Bytes deep_copy(uint8_t *data, size_t size, uint8_t offset=0) noexcept
Creates an owned deep copy of an external mutable buffer.
压缩支持(LZAV)
compressed.data(), compressed.size());
}
true);
static Bytes compress_data(const uint8_t *data, size_t size, bool high_ratio=false) noexcept
Compresses a raw byte buffer using the LZAV algorithm.
static Bytes uncompress_data(const uint8_t *data, size_t size, bool check_valid=true) noexcept
Decompresses a LZAV-compressed Bytes buffer.
static bool is_compress_data(const uint8_t *data, size_t size) noexcept
Checks whether a raw byte buffer contains LZAV-compressed VLink data.
compress_data() 对输入大小上限为 kMaxCompressCacheSize(1 MiB), 超出会返回空 Bytes。
工具函数
static Bytes reverse_order(const Bytes &target) noexcept
Returns a new Bytes object with the byte order of target reversed.
static void init_memory_pool() noexcept
Initialises the global thread-safe memory pool for Bytes allocations.
static Bytes decode_from_base64(const std::string &target) noexcept
Decodes a Base-64 ASCII string into a Bytes buffer.
static std::string encode_to_base64(const Bytes &target) noexcept
Encodes a Bytes buffer as a standard Base-64 ASCII string.
static uint32_t get_crc_32(const Bytes &target) noexcept
Computes the CRC-32 checksum of a Bytes buffer.
static std::string convert_to_hex_str(const uint8_t *value, size_t size) noexcept
Converts a raw byte array to an uppercase hex string with spaces.
static void release_memory_pool() noexcept
Releases the global memory pool and returns its memory to the OS.
11.4 消息循环 MessageLoop
vlink::MessageLoop 是 VLink 中的核心任务调度器,也是定时器、Schedule 等机制的基础。 它实现了一个**单线程串行事件循环**:所有任务在同一个线程上顺序执行, 回调内部无需加锁即可安全访问共享状态。
核心概念
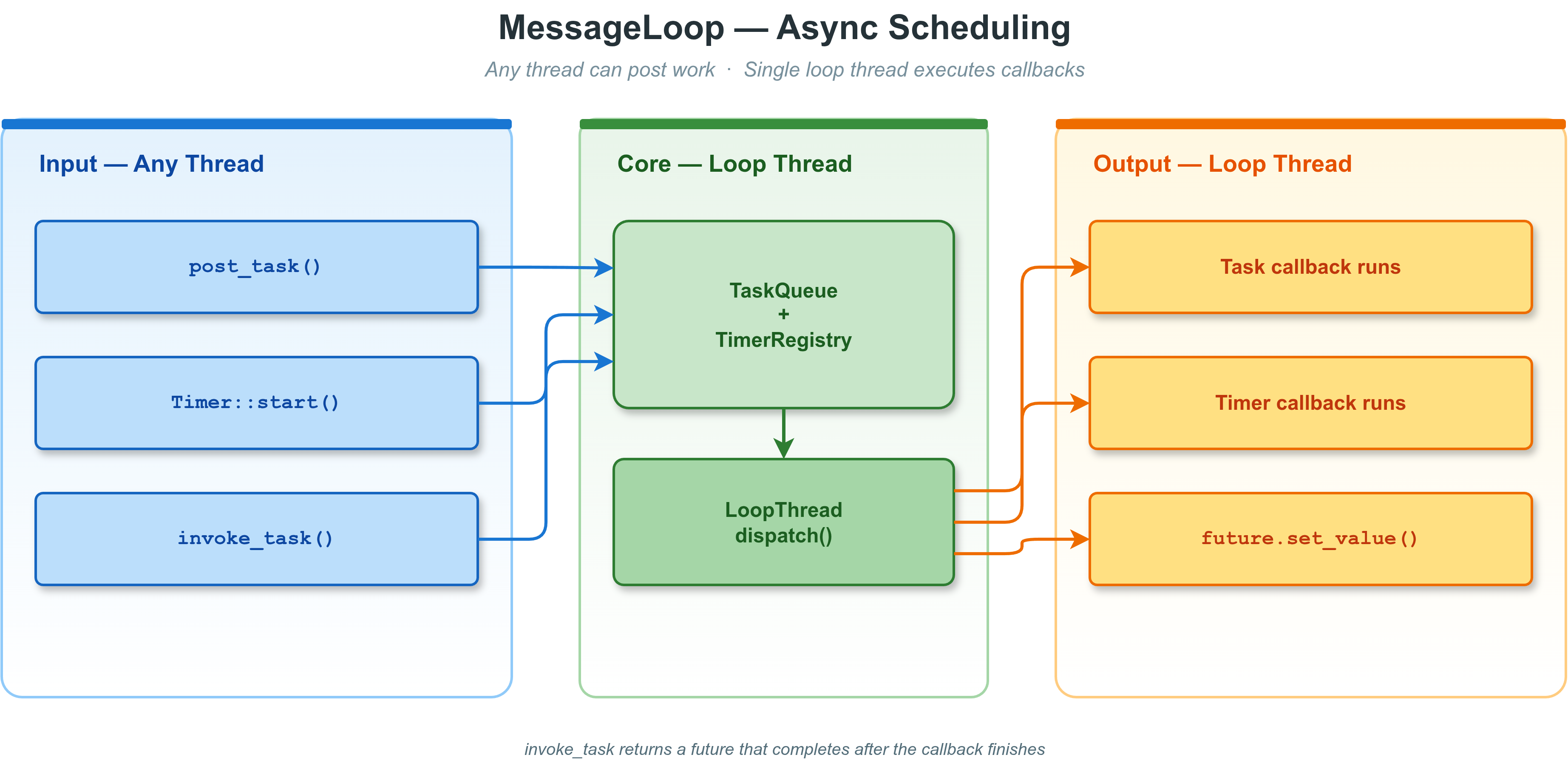
MessageLoop 核心概念
- **单线程串行**:所有投递到同一个 MessageLoop 的任务严格串行,不会并发。
- **线程安全投递**:post_task() 本身是线程安全的,可从任意线程调用。
- **集成定时器**:Timer attach 到 MessageLoop 后,定时回调与普通任务共用同一线程。
- **最大队列深度**:默认 10000(kMaxTaskSize),超出时 post_task() 返回 false。
- **最大定时器数**:默认 100(kMaxTimerSize),超出时 Timer::attach() 失败。
队列类型
| 类型(Type) | 内部实现 | 最大任务数 | 特点 |
| kNormalType | mutex + std::queue | 10000 | 默认,FIFO 无优先级 |
| kLockfreeType | 无锁 MpmcQueue | 10000 | 单生产者路径最快 |
| kPriorityType | 优先级队列 | 10000 | 支持任务优先级,数值大先执行 |
空闲策略
| 策略(Strategy) | 行为 | 适用场景 |
| kOptimizationStrategy | yield 平衡延迟与 CPU 使用率 | 默认,通用 |
| kPopStrategy | 忙轮询,持续检测队列(最低延迟) | 实时性要求极高 |
| kBlockStrategy | 条件变量阻塞等待任务(最低 CPU) | 低频任务、省电场景 |
运行模式
run() – 阻塞运行
在**调用线程**上运行事件循环,阻塞直到 quit() 被调用。 适合主线程驱动的模型。
std::thread stopper([&] {
std::this_thread::sleep_for(std::chrono::seconds(5));
});
stopper.join();
Single-threaded serial task dispatcher with integrated timer support.
Definition message_loop.h:106
void register_begin_handler(Callback &&callback)
Registers a callback invoked once when the loop thread starts.
bool run()
Runs the message loop on the calling thread (blocking).
void register_end_handler(Callback &&callback)
Registers a callback invoked once when the loop thread exits.
bool quit(bool force=false)
Requests the loop to exit cleanly.
async_run() – 后台线程运行
立即在**新后台线程**上启动循环,调用线程不阻塞。 这是最常用的模式。
bool async_run()
Starts the message loop on a new background thread (non-blocking).
bool wait_for_quit(int ms=Timer::kInfinite, bool check=true)
Waits until the loop has fully exited (after quit() was called).
bool post_task(Callback &&callback)
Posts a task to the queue for execution on the loop thread.
spin() / spin_once() – 手动驱动
将 MessageLoop 嵌入已有事件循环,手动驱动。
while (app_running) {
do_other_work();
}
bool spin_once(bool block=true)
Processes one batch of pending tasks and timers.
基本任务投递
post_task()
VLOG_I(
"hello from loop thread");
});
std::string data = "sensor_data";
process(data);
});
post_task_with_priority()
仅对 kPriorityType 类型的循环有效,其他类型退化为 FIFO。
ploop.async_run();
ploop.post_task_with_priority(
[] { handle_critical_alert(); },
ploop.post_task_with_priority(
[] { handle_normal_msg(); },
@ kPriorityType
Priority-ordered queue.
Definition message_loop.h:122
@ kHighestPriority
Highest available priority.
Definition message_loop.h:149
@ kNormalPriority
Default task priority.
Definition message_loop.h:148
MessageLoop 预定义优先级常量:
| 常量 | 值 | 说明 |
| kNoPriority | 0 | 无优先级,按 FIFO 顺序执行 |
| kLowestPriority | 1 | 最低优先级 |
| kTimerPriority | 50 | 内部定时器默认使用 |
| kNormalPriority | 100 | 标准应用任务 |
| kHighestPriority | 65535 | 最高优先级,紧急/实时任务 |
注意:优先级值越大越先执行。仅 kPriorityType 队列支持优先级调度,其他队列类型忽略优先级参数,退化为 FIFO 顺序。 QoS 扩展字段 Qos::Additions::Priority 是独立于 MessageLoop 优先级的另一套枚举,详见 08-qos.md。
invoke_task() – 带返回值
从**外部线程**投递任务并等待结果,通过 std::future 获取返回值。
return expensive_compute();
});
int result = future.get();
std::future< ResultT > invoke_task(FunctionT &&function, ArgsT &&... args)
Dispatches a callable to the loop thread and returns a std::future for the result.
Definition message_loop.h:609
**警告**: 绝对不要在循环**自身的线程**上调用 future.get()。 这会导致死锁:任务等待被执行,而线程在等待任务,互相阻塞。 使用 is_in_same_thread() 检测当前是否在循环线程内。
auto fut = loop.
invoke_task([]{
return get_state(); });
auto state = fut.get();
} else {
auto state = get_state();
}
virtual bool is_in_same_thread() const
Returns true if the calling thread is the same as the loop thread.
与定时器集成
Timer 绑定到 MessageLoop 后,定时回调与普通任务共用**同一线程**。
});
});
Event-loop-driven repeating or one-shot timer.
Definition timer.h:81
static bool call_once(class MessageLoop *message_loop, uint32_t interval_ms, Callback &&callback, uint16_t priority=0)
Posts a one-shot timer to a MessageLoop without creating a Timer object.
void start(Callback &&callback=nullptr)
Arms and starts the timer.
static constexpr int kInfinite
Sentinel loop count meaning repeat indefinitely.
Definition timer.h:91
延迟执行通过 exec_task 的 Schedule::Config::delay_ms 或 Timer::call_once 实现;周期执行直接用 Timer(见上文示例)。
exec_task – 带调度配置的任务
exec_task() 是比 post_task() 更强大的投递接口,支持链式延续回调。
void 回调
100,
50,
500,
200
},
[] {
long_running_op();
})
.on_schedule_timeout([] {
VLOG_W(
"task was not scheduled in time");
})
.on_execution_timeout([] {
VLOG_W(
"task execution took too long");
})
.on_catch([](std::exception& e) {
VLOG_E(
"exception: ", e.what());
});
Schedule::Status exec_task(const Schedule::Config &config, CallbackT &&callback)
Posts a scheduled task and returns a Schedule::Status for chaining callbacks.
Definition message_loop.h:557
#define VLOG_E(...)
Definition logger.h:854
#define VLOG_W(...)
Definition logger.h:852
Scheduling parameters for a task posted via MessageLoop::exec_task().
Definition schedule.h:121
bool 回调(带结果链)
[]() -> bool {
return try_connect_to_server();
})
.on_then([]() -> bool {
return do_auth();
})
.on_then([]() -> bool {
subscribe_all();
return true;
})
.on_else([] {
VLOG_W(
"connection or auth failed, will retry");
schedule_retry();
});
生命周期管理
bool is_running() const
Returns true if the loop is currently running (started and not quit).
bool is_busy() const
Returns true if the loop is currently executing a task.
bool is_ready_to_quit() const
Returns true if quit() has been called and the loop is winding down.
size_t get_task_count() const
Returns the number of tasks currently in the queue.
bool wait_for_idle(int ms=Timer::kInfinite, bool check=true)
Waits until the task queue is drained.
生命周期回调钩子
VLOG_I(
"loop thread started");
});
VLOG_I(
"loop thread stopping");
});
});
void register_idle_handler(Callback &&callback)
Registers a callback invoked each time the task queue becomes empty.
VLINK_EXPORT bool set_thread_name(const std::string &name, std::thread *thread=nullptr) noexcept
Sets the OS-level name of a thread for debugging tools (e.g., gdb, perf).
也可以通过继承重载虚函数,实现更细粒度的监控:
protected:
}
}
}
}
VLOG_W(
"slow task: ", elapsed_ms,
" ms");
}
};
virtual void on_task_changed(Callback &&callback, uint32_t start_time)
Called before each task is executed.
virtual void on_end()
Called from the loop thread just after the last task has been processed.
virtual void on_idle()
Called from the loop thread each time the queue becomes empty.
virtual void on_task_timeout(Callback &&callback, uint32_t elapsed_time)
Called when a task's execution time exceeds get_max_elapsed_time().
virtual void on_begin()
Called from the loop thread just before the first task is processed.
在通信回调中使用 MessageLoop
VLink 的通信回调(Subscriber、Server 等)在传输层的**内部线程**上触发。 将收到的消息 post 到自己的 MessageLoop 是串行化处理的标准模式:
sub.listen([&](const MyMsg& msg) {
auto copy = msg;
my_loop.
post_task([copy = std::move(copy)]() {
process_message(copy);
});
});
Type-safe subscriber for the VLink event communication model.
Definition subscriber.h:110
多 MessageLoop 场景
每个模块可以拥有独立的 MessageLoop,实现关注点分离:
SensorData data = read_sensor();
apply_control(data);
});
});
不同循环间通过 post_task() 传递消息是线程安全的。
与 ThreadPool 配合
MessageLoop 串行、ThreadPool 并行,常见模式是把 CPU 密集型任务下发到 ThreadPool,结果通过 post_task() 回到 MessageLoop 进行串行更新:
compute_pool.post_task([&] {
auto result = heavy_compute();
update_ui(result);
});
});
});
Fixed-size thread pool for parallel task execution.
Definition thread_pool.h:80
线程安全说明
| 操作 | 是否线程安全 | 说明 |
| post_task() | 是 | 可从任意线程并发调用 |
| post_task_with_priority() | 是 | 同上 |
| invoke_task() | 是,但有注意 | 不能在同一循环线程上 .get() |
| quit() | 是 | 可从任意线程调用 |
| is_running() / is_busy() | 是 | 状态读取 |
| run() / async_run() | 否 | 只能从构造循环的线程调用一次 |
| 循环线程内访问共享状态 | 安全 | 串行,无数据竞争 |
| 多个循环线程访问同一共享状态 | 不安全 | 需要额外同步(mutex/原子量) |
注意事项与常见陷阱
死锁
int v = fut.get();
});
int v = fut.get();
}
递归调用
post_task() 可以在循环线程内调用(从正在执行的任务中投递新任务),这是安全的:
但不要在任务内调用 wait_for_idle(),这会导致阻塞自身。
队列满
if (!ok) {
VLOG_W(
"queue full, task dropped");
}
通过继承重载 get_max_task_count() 调整队列上限:
public:
};
virtual size_t get_max_task_count() const
Returns the maximum queue depth.
长时间任务阻塞循环
MessageLoop 是单线程的。一个耗时很长的任务会阻塞所有其他任务(包括定时器)。 对于耗时操作,应使用 ThreadPool 异步执行,完成后 post 结果。
完整示例:定时任务 + 异步回调串行化
});
});
});
[]() -> bool {
return connect_to_remote();
})
.on_then([]() -> bool {
subscribe_topics();
return true;
})
.on_else([] { schedule_reconnect(); })
.on_execution_timeout([] {
VLOG_W(
"connect timed out"); });
});
Single-threaded event loop with three queue types, timer management and task scheduling.
RAII task scheduling wrapper with delay, priority, timeouts and result chaining.
Event-loop-driven periodic/one-shot timer with configurable priority.
11.5 定时器
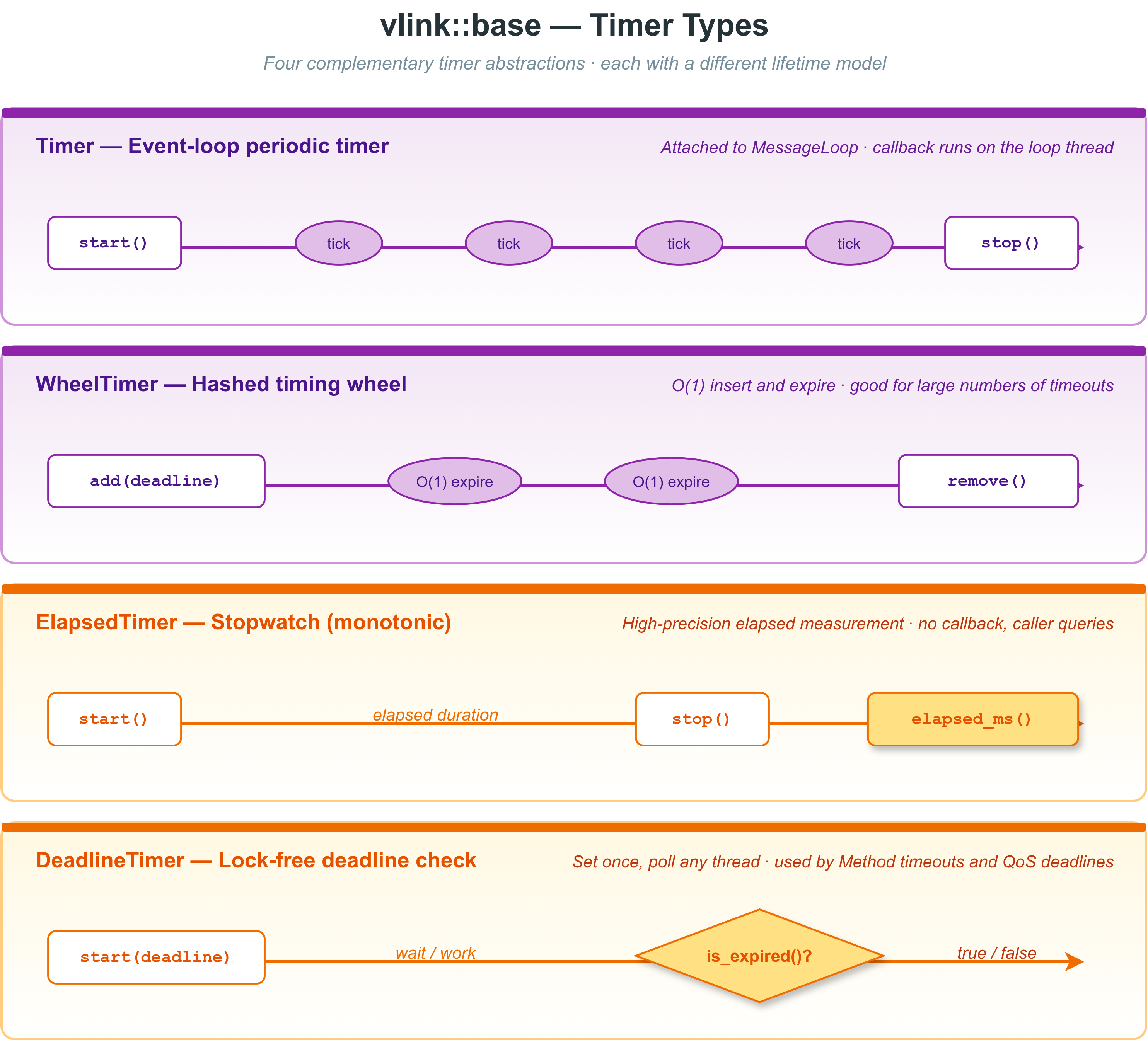
定时器类型对比
Timer – 事件循环定时器
概述
vlink::Timer 与 MessageLoop 集成,回调在循环线程上串行触发,无需额外同步。 当 interval_ms 传入 0 时,间隔会回退到内部的 kMinInterval 保护值。
构造与使用
严格模式
主要 API
timer.start();
timer.stop();
timer.restart();
timer.set_interval(100);
timer.set_loop_count(10);
timer.set_callback([]{ ... });
timer.set_priority(100);
timer.set_strict(true);
timer.is_active();
timer.get_invoke_count();
timer.get_remain_loop_count();
timer.get_priority();
timer.attach(&loop);
timer.detach();
WheelTimer – 哈希时间轮定时器
概述
vlink::WheelTimer 使用哈希时间轮算法管理**大量并发超时**(数十万级别), 插入、删除均为 O(1),适合连接保活、会话超时等场景。
时间轮参数:
- slots:时间槽数量,决定最大无折叠精度范围(slots * interval_ms)
- interval_ms:每个槽的时间(毫秒),所有定时器分辨率
超过 slots * interval_ms 的超时通过轮次计数器处理,仍为 O(1)。
使用示例
wheel.start();
});
}, 500);
wheel.remove(key);
uint32_t remaining = wheel.get_remaining_time(repeat_key);
wheel.pause();
wheel.resume();
wheel.set_catchup_limit(10);
wheel.stop();
O(1) hash-wheel timer backed by a fixed-size circular slot array.
Definition wheel_timer.h:89
int64_t Key
Opaque handle returned by add() and used to remove() a timer.
Definition wheel_timer.h:94
Hash-wheel timer for managing large numbers of concurrent timeouts efficiently.
**注意**:回调在 WheelTimer 内部工作线程上调用,需要线程安全操作。 通常将结果 post 到 MessageLoop 处理。
ElapsedTimer – 高精度计时器
概述
vlink::ElapsedTimer 测量从 start() 调用开始的经过时间,支持两种时钟源和三种精度。
| 时钟源(Method) | 描述 |
| kCpuTimestamp | 单调墙钟(Linux CLOCK_MONOTONIC_RAW) |
| kCpuActiveTime | 进程 CPU 活跃时间(user + kernel) |
| 精度(Accuracy) | 单位 |
| kMilli | 毫秒 |
| kMicro | 微秒 |
| kNano | 纳秒 |
使用示例
do_work();
cpu_t.start();
heavy_compute();
int64_t cpu_us = cpu_t.get();
Atomic, high-resolution elapsed-time timer.
Definition elapsed_timer.h:93
void start() noexcept
Starts the timer if it is not already active.
bool is_active() const noexcept
Returns true when the timer has been started and not yet stopped.
static uint64_t get_cpu_timestamp(Accuracy accuracy=kMilli, bool high_resolution=true) noexcept
Returns the current monotonic CPU timestamp.
int64_t get() const noexcept
Returns the elapsed time since start() was called.
int64_t restart() noexcept
Atomically resets the start time to now and returns the elapsed time since the previous start() / res...
@ kNano
Nanosecond precision.
Definition elapsed_timer.h:109
@ kMicro
Microsecond precision.
Definition elapsed_timer.h:108
void stop() noexcept
Stops the timer, setting the internal start time to -1.
static uint64_t get_sys_timestamp(Accuracy accuracy=kMilli, bool high_resolution=true) noexcept
Returns the current wall-clock (system) timestamp.
@ kCpuActiveTime
Process CPU time (user + kernel, via getrusage).
Definition elapsed_timer.h:100
High-resolution elapsed-time measurement with configurable clock source and precision.
性能测量惯用法
bench.start();
for (int i = 0; i < 10000; i++) {
do_operation();
}
int64_t total_us = bench.get();
VLOG_I(
"avg latency = ", (total_us / 10000),
" us");
DeadlineTimer – 绝对截止时间定时器
概述
vlink::DeadlineTimer 存储一个绝对到期时间戳(原子 64 位),用于**无锁超时检测**。 多线程并发读取 has_expired() 或 remaining_time() 无需加锁。
while (!dt.has_expired()) {
process_events();
}
int64_t left = dt.remaining_time();
dt.set_deadline(500);
dt.set_deadline_abs(abs + 1000);
dt.reset();
Atomic absolute-deadline timer for lock-free timeout detection.
Definition deadline_timer.h:88
An absolute-deadline timer for lightweight, lock-free timeout tracking.
remaining_time() 返回 0 同时可能意味着"无效"或"已过期"; 在做精确判断时应结合 is_valid() 使用。
11.6 线程池 ThreadPool
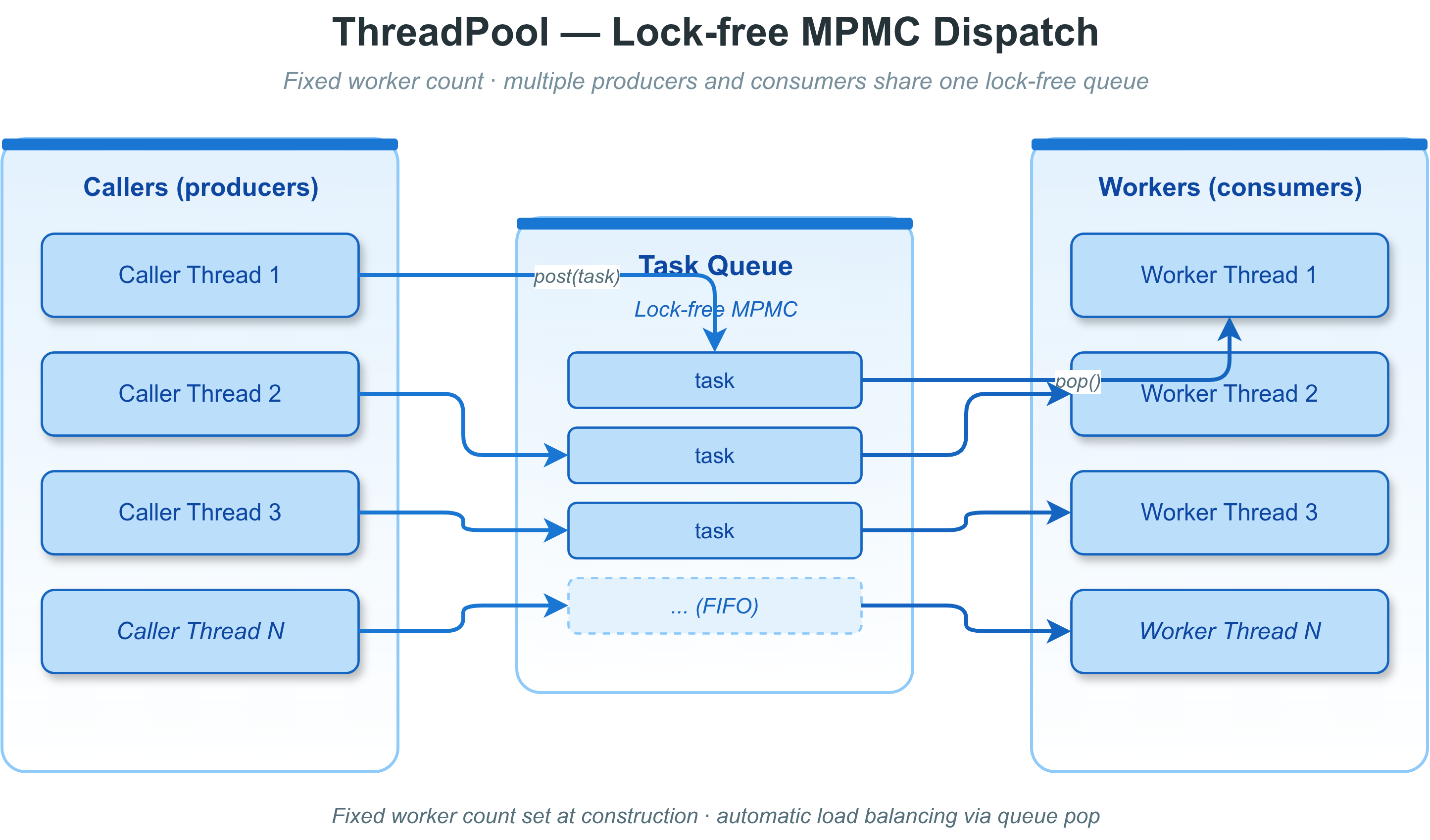
线程池架构
概述
vlink::ThreadPool 维护固定数量的工作线程,用于**并行执行**任务。 与 MessageLoop 的区别:无定时器支持,任务可并发执行,适合 CPU 密集型工作。
队列类型与空闲策略
| 类型(Type) | 内部队列 | 说明 |
| kNormalType | mutex + std::queue | 默认,通用 |
| kLockfreeType | 无锁 MPMC 队列 | 低竞争延迟 |
| 策略(Strategy) | 行为 |
| kOptimizationStrategy | yield 平衡延迟与 CPU |
| kPopStrategy | 忙轮询,最低延迟最高 CPU |
| kBlockStrategy | 条件变量阻塞,最低 CPU |
使用示例
pool.set_name("compute-pool");
pool.post_task([] {
heavy_work();
});
auto fut = pool.invoke_task([]() -> int {
return compute_answer();
});
int result = fut.get();
size_t pending = pool.get_task_count();
if (!pool.is_in_work_thread()) {
auto inner_fut = pool.invoke_task([]{ return 42; });
inner_fut.get();
}
pool.shutdown();
@ kBlockStrategy
Block on condition variable (lowest CPU).
Definition thread_pool.h:101
General-purpose thread pool for parallel task execution.
**警告**:在线程池的工作线程内调用 invoke_task(...).get() 会死锁! 使用 is_in_work_thread() 检测,或改用 post_task()。
11.7 进程管理 Process
vlink::Process 是 VLink 基础库提供的跨平台子进程管理类,API 设计参考了 Qt 的 QProcess, 用于启动、监控、通信和终止子进程。它支持 stdout/stderr 的管道捕获、stdin 写入、 异步回调通知,以及同步执行辅助方法,可在 Linux、macOS、Windows 和 QNX 上使用。
概述
在自动驾驶和具身智能场景中,经常需要从主进程启动并管理外部程序(如传感器驱动、数据采集工具、 诊断程序等)。Process 封装了底层的 fork/exec(POSIX)和 CreateProcess(Windows)调用, 提供统一的 C++ 接口完成以下工作:
- 启动子进程并传递命令行参数
- 配置子进程的环境变量和工作目录
- 通过管道捕获子进程的标准输出和标准错误
- 向子进程的标准输入写入数据
- 注册异步回调,在数据可读、状态变化或进程退出时获得通知
- 优雅终止(SIGTERM)或强制杀死(SIGKILL)子进程
- 提供静态方法 execute() 和 start_detached() 用于简化的同步执行和分离启动
头文件
Cross-platform child process management with I/O piping and async callbacks.
生命周期状态
Process 内部维护一个三态状态机:
| 状态 | 数值 | 说明 |
| kNotRunningState | 0 | 未启动或已退出 |
| kStartingState | 1 | start() 已调用,正在等待 exec 完成 |
| kRunningState | 2 | 子进程正在运行 |
状态转换流程:
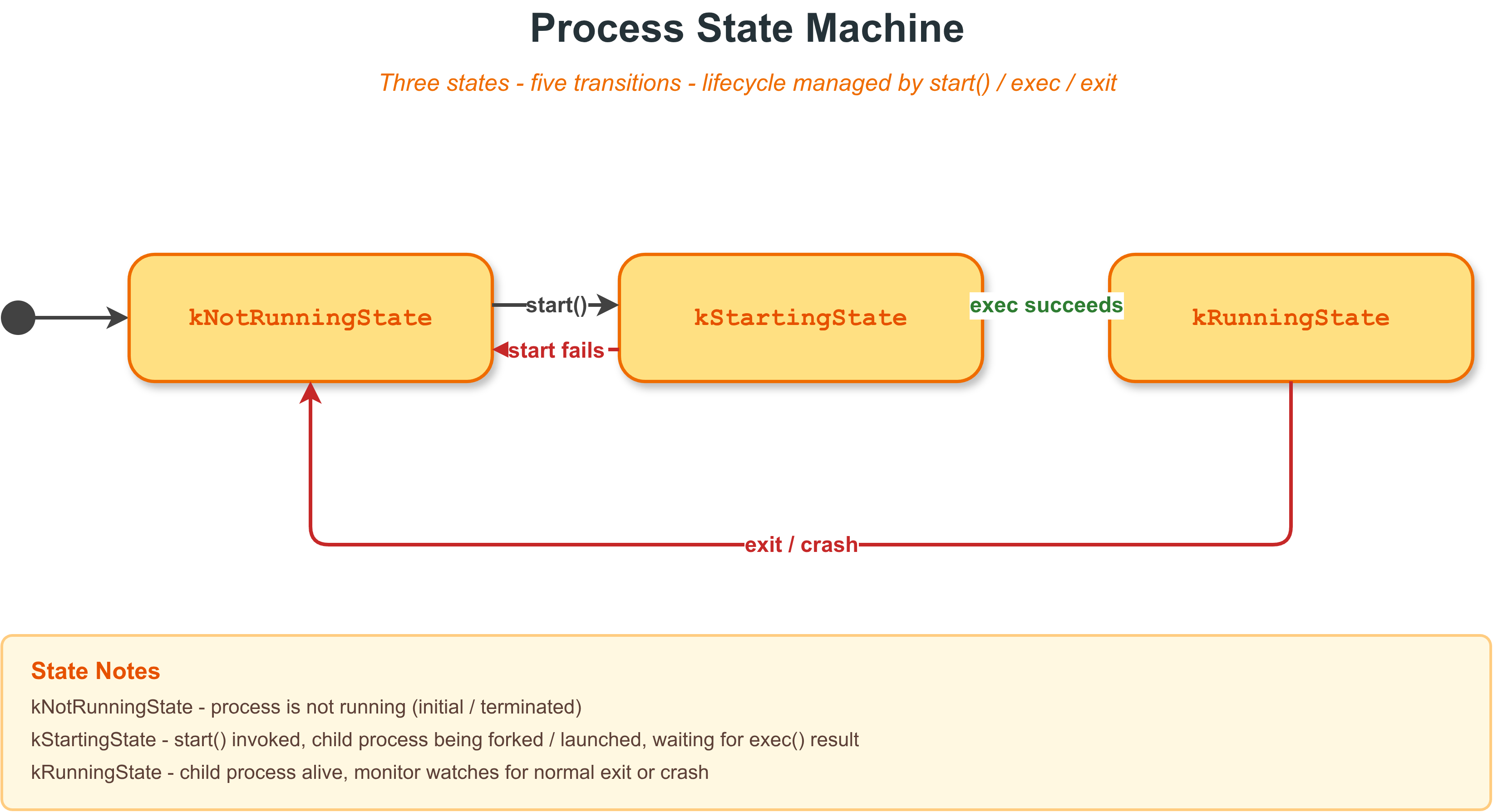
Process 状态机
通过 get_state() 查询当前状态,通过 is_running() 快速判断是否正在运行。
退出状态
| 枚举 | 数值 | 说明 |
| kNormalExitStatus | 0 | 子进程正常退出(exit() 或 main 返回) |
| kCrashExitStatus | 1 | 子进程被信号杀死或崩溃 |
错误码
| 枚举 | 数值 | 说明 |
| kNoError | 0 | 无错误 |
| kUnknownError | 1 | 未知错误 |
| kStartError | 2 | 启动失败(如可执行文件不存在) |
| kCrashedError | 3 | 子进程崩溃 |
| kTimedOutError | 4 | 等待操作超时 |
| kWriteError | 5 | 写入 stdin 失败 |
| kReadError | 6 | 读取 stdout/stderr 失败 |
| kBufferOverflowError | 7 | 输出超出 max_buffer_size 限制 |
I/O 通道模式
Process::Mode 控制子进程的 stdout 和 stderr 如何路由。必须在 start() 之前通过 set_process_mode() 设置。
| 模式 | 数值 | stdout | stderr | 适用场景 |
| kSeparateMode | 0 | 缓冲到管道 | 缓冲到管道 | 需要分别读取 stdout/stderr |
| kMergedMode | 1 | 缓冲到管道 | 合并到 stdout 管道 | 不区分 stdout/stderr |
| kForwardedMode | 2 | 转发到父进程 | 转发到父进程 | 子进程输出直接显示在终端 |
| kForwardedOutputMode | 3 | 转发到父进程 | 缓冲到管道 | stdout 直接显示,stderr 捕获 |
| kForwardedErrorMode | 4 | 缓冲到管道 | 转发到父进程 | stdout 捕获,stderr 直接显示 |
注意事项:
- 在 kForwardedMode 下,read_all_output() 和 read_all_error() 不会返回数据, 因为输出被直接转发到了父进程的终端。
- 在 kMergedMode 下,所有子进程输出都通过 read_all_output() 读取, read_all_error() 不会有数据。
- 默认模式为 kSeparateMode。
Cross-platform child process with async I/O and state notification.
Definition process.h:93
@ kSeparateMode
stdout and stderr buffered as separate pipes
Definition process.h:130
void set_process_mode(Mode mode)
Sets the I/O channel routing mode.
核心 API
构造与析构
析构函数的行为:
- 如果子进程仍在运行,先发送 terminate()(SIGTERM)
- 等待 kDestructorWaitTimeoutMs(5000 ms)
- 如果仍未退出,发送 kill()(SIGKILL)
- 再等待 1000 ms 后清理资源
Process 不可拷贝、不可移动。
start()
void start(const std::string& program, const std::vector<std::string>& arguments = {});
异步启动子进程。调用后进程状态从 kNotRunningState 转为 kStartingState, 成功后转为 kRunningState。如果已有进程在运行,则设置 kStartError 并返回。
proc.
start(
"/bin/echo", {
"hello",
"world"});
void start(const std::string &program, const std::vector< std::string > &arguments={})
Launches the child process.
bool wait_for_started(int msecs=kDefaultWaitTimeoutMs)
Blocks until the child process enters kRunningState.
start_command()
void start_command(const std::string& command);
将一个完整的命令行字符串按空白字符拆分为程序名和参数列表,然后调用 start()。 支持双引号、单引号和转义字符。
void start_command(const std::string &command)
Parses and launches a shell command string.
等待
bool wait_for_started(int msecs = kDefaultWaitTimeoutMs);
bool wait_for_finished(int msecs = kDefaultWaitTimeoutMs);
bool wait_for_ready_read(int msecs = kDefaultWaitTimeoutMs);
- wait_for_started():阻塞等待子进程进入 kRunningState。传入 kInfinite(-1)表示无限等待。
- wait_for_finished():阻塞等待子进程退出。
- wait_for_ready_read():阻塞等待管道中有新数据可读。
终止子进程
void terminate();
void kill();
void close(bool force_kill_on_timeout = false);
proc.
start(
"/bin/sleep", {
"60"});
void close(bool force_kill_on_timeout=false)
Calls terminate() and optionally force-kills after a timeout.
状态查询
State get_state() const;
Error get_error() const;
int get_exit_code() const;
ExitStatus get_exit_status() const;
bool is_running() const;
int64_t get_process_id() const;
异步回调
所有回调均在内部监控线程中被调用,访问共享数据时需要注意线程安全。 回调必须在 start() 之前注册。
MLOG_I(
"Process exited with code: {}", code);
} else {
}
});
std::string line;
}
});
switch (state) {
VLOG_I(
"Process starting...");
break;
break;
break;
}
});
bool can_read_line_stdout() const
Returns true if a complete newline-terminated line is available on stdout.
void register_ready_read_stderr_callback(ReadyReadCallback &&callback)
Registers a callback invoked when new stderr data is available.
void register_error_callback(ErrorCallback &&callback)
Registers a callback for error events.
ExitStatus
How the child process exited.
Definition process.h:107
@ kNormalExitStatus
Exited normally (via exit() or return from main).
Definition process.h:108
bool read_line_stdout(std::string &line)
Reads one line from stdout into line.
void register_ready_read_stdout_callback(ReadyReadCallback &&callback)
Registers a callback invoked when new stdout data is available.
void register_state_changed_callback(StateChangedCallback &&callback)
Registers a callback invoked when the process state changes.
State
Lifecycle state of the child process.
Definition process.h:98
@ kStartingState
start() called; waiting for exec to complete
Definition process.h:100
@ kRunningState
Successfully running.
Definition process.h:101
@ kNotRunningState
Not started or has exited.
Definition process.h:99
void register_finished_callback(FinishedCallback &&callback)
Registers a callback invoked when the child exits.
Error
Error codes set on failure.
Definition process.h:115
#define MLOG_I(...)
Definition logger.h:874
读写操作
读取 stdout
| 方法 | 说明 |
| bytes_available_stdout() | 返回 stdout 缓冲区中可读字节数 |
| can_read_line_stdout() | 是否有完整的一行(以换行符结尾) |
| read_line_stdout(std::string& line) | 读取一行(含换行符),从缓冲区移除 |
| read_stdout(std::vector<uint8_t>& buf, size_t) | 读取指定字节数到字节数组 |
| read_all_output(std::string& str) | 读取全部 stdout 数据到字符串 |
| read_all_output(std::vector<uint8_t>& buf) | 读取全部 stdout 数据到字节数组 |
读取 stderr
| 方法 | 说明 |
| bytes_available_stderr() | 返回 stderr 缓冲区中可读字节数 |
| can_read_line_stderr() | 是否有完整的一行 |
| read_line_stderr(std::string& line) | 读取一行 |
| read_stderr(std::vector<uint8_t>& buf, size_t) | 读取指定字节数 |
| read_all_error(std::string& str) | 读取全部 stderr 数据到字符串 |
| read_all_error(std::vector<uint8_t>& buf) | 读取全部 stderr 数据到字节数组 |
读取全部输出(stdout + stderr 合并)
| 方法 | 说明 |
| read_all(std::string& str) | 读取 stdout + stderr 合并到字符串 |
| read_all(std::vector<uint8_t>& buf) | 读取 stdout + stderr 合并到字节数组 |
写入 stdin
size_t write(const std::vector<uint8_t>& buffer, int timeout_ms = kDefaultWriteTimeoutMs);
size_t write(const std::string& str, int timeout_ms = kDefaultWriteTimeoutMs);
向子进程的标准输入写入数据。返回实际写入的字节数。默认超时 5000 ms。
proc.
write(
"hello_stdin\n");
std::string output;
size_t write(const std::vector< uint8_t > &buffer, int timeout_ms=kDefaultWriteTimeoutMs)
Writes buffer to the child's stdin.
void close_write_channel()
Closes the write channel (stdin pipe), signalling EOF to the child.
bool wait_for_finished(int msecs=kDefaultWaitTimeoutMs)
Blocks until the child process exits.
bool read_all_output(std::vector< uint8_t > &buffer)
Reads all available stdout data into buffer (byte vector overload).
同步辅助方法
Process::execute()
static int execute(const std::string& program,
const std::vector<std::string>& arguments = {},
int timeout_ms = kDefaultExecuteTimeoutMs);
静态方法,同步执行一个外部程序并等待其完成。返回退出码,超时或启动失败返回 -1。
static int execute(const std::string &program, const std::vector< std::string > &arguments={}, int timeout_ms=kDefaultExecuteTimeoutMs)
Synchronously executes a program and waits for it to finish.
Process::start_detached()
static bool start_detached(const std::string& program,
const std::vector<std::string>& arguments = {});
静态方法,启动一个完全分离的子进程。分离的进程与父进程无关,父进程退出不影响它。
POSIX 实现:双 fork() + setsid(),孙进程被 init 收养,stdin/stdout/stderr 重定向到 /dev/null。
static bool start_detached(const std::string &program, const std::vector< std::string > &arguments={})
Starts a program in the background and returns immediately.
缓冲区管理
void set_max_buffer_size(size_t size);
size_t get_max_buffer_size() const;
当子进程输出超过此限制时,多余数据被丢弃,并设置 kBufferOverflowError。
环境变量与工作目录
void set_inherit_environment(bool inherit)
Controls whether the child inherits the parent's environment.
void set_environment(const EnvironmentMap &env_map)
Sets the environment variables for the child process.
void set_working_directory(const std::string &dir)
Sets the working directory for the child process.
内部常量
| 常量 | 值 | 说明 |
| kInfinite | -1 | 无限等待标记 |
| kDefaultWaitTimeoutMs | 3000 | wait_for_started/finished 默认超时 |
| kDefaultWriteTimeoutMs | 5000 | write() 默认超时 |
| kDefaultExecuteTimeoutMs | 30000 | execute() 默认超时 |
| kDestructorWaitTimeoutMs | 5000 | 析构函数等待子进程退出的超时 |
| 默认缓冲区大小(内部) | 16 MB | stdout/stderr 缓冲区上限 |
| 管道读取块大小(内部) | 8192 | 每次从管道读取的最大字节数 |
| 监控线程轮询间隔(内部) | 50 ms | poll/waitpid 的超时时间 |
跨平台注意事项
- **Linux / macOS**:使用 fork() + execvp()/execve(),管道使用 pipe() + dup2(),非阻塞 O_NONBLOCK,poll() 检测数据就绪。
- **Windows**:使用 CreateProcessW() + CreatePipe(),重叠 I/O 读取管道,WaitForSingleObject() 等待退出。
- **QNX**:与 Linux 类似使用 POSIX API,sysconf(_SC_OPEN_MAX) 获取最大 fd 数。
- Process 不可拷贝、不可移动,同一对象同一时间只能管理一个子进程。
完整示例
捕获子进程输出
#include <iostream>
#include <string>
int main() {
proc.
start(
"/bin/echo", {
"hello",
"vlink"});
std::string output;
std::cout << "Output: " << output << std::endl;
return 0;
}
异步监听子进程输出
#include <iostream>
#include <string>
int main() {
std::string line;
std::cout << "Received: " << line;
}
});
std::cout << "Process finished, exit code: " << code << std::endl;
});
proc.
start(
"/bin/sh", {
"-c",
"echo line1; echo line2; echo line3"});
return 0;
}
与子进程交互(读写 stdin/stdout)
#include <iostream>
#include <string>
int main() {
proc.
write(
"hello from parent\n");
proc.
write(
"another line\n");
std::string output;
std::cout << output;
return 0;
}
11.8 并发原语
并发组件对比表
任务调度组件对比
| 特性 | MessageLoop | ThreadPool | MultiLoop |
| 执行模型 | 单线程串行 | 固定线程池并行 | 事件循环 + 线程池并行 |
| 任务顺序保证 | 严格 FIFO | 无保证 | 无保证 |
| 定时器支持 | 支持 | 不支持 | 支持(继承自 MessageLoop) |
| 生命周期管理 | run/quit/async_run | 构造即启动/shutdown | async_run/quit(继承) |
| 队列类型 | Normal/Lockfree/Priority | Normal/Lockfree | Normal/Lockfree/Priority |
| API 兼容性 | 基类 | 独立 | 与 MessageLoop 完全兼容 |
| 适用场景 | 有序任务派发 | 纯计算并行 | 需要定时器又需要并行处理的场景 |
同步原语对比
| 特性 | SpinLock | std::mutex | Semaphore |
| 等待方式 | 自旋(用户态) | 内核态阻塞 | 条件变量阻塞 |
| 适用临界区长度 | 极短(几条指令) | 任意 | 不限 |
| 上下文切换 | 无 | 有 | 有 |
| 公平性 | 无保证 | 由 OS 调度 | FIFO |
| 递归支持 | 不支持(会死锁) | 可用 recursive_mutex | 不适用 |
| CPU 占用 | 高(忙等待) | 低(休眠) | 低(休眠) |
MultiLoop 多线程循环
MultiLoop 继承自 MessageLoop,保持了完全相同的 post_task() / exec_task() / invoke_task() API。核心区别在于 on_task_changed() 方法被重写:任务不再在事件循环线程上直接执行,而是被转发到内部的 ThreadPool 上并行执行。
架构示意:
post_task()
调用方 ---------> MessageLoop 队列 ---------> on_task_changed()
|
ThreadPool (N 个工作线程)
/ | | \
thread0 t1 t2 thread(N-1)
关键特性:
- N 个工作线程共享同一个任务队列
- 任务不保证执行顺序
- is_in_same_thread() 对任何工作线程返回 true
- on_begin() 和 on_end() 在每个工作线程上各调用一次
- 定时器回调在某个工作线程上触发(非确定性)
- 析构函数等待所有工作线程结束
构造参数
Multi-threaded variant of MessageLoop running tasks on a worker-thread pool.
Definition multi_loop.h:74
核心 API
auto fut = loop.
invoke_task([]() ->
int {
return compute(); });
int result = fut.get();
bool post_task_with_priority(Callback &&callback, uint16_t priority)
Posts a task with an explicit priority (requires kPriorityType loop).
完整示例
#include <atomic>
#include <iostream>
int main() {
std::atomic<int> counter{0};
constexpr int kTasks = 100;
for (int i = 0; i < kTasks; ++i) {
counter.fetch_add(1, std::memory_order_relaxed);
});
}
std::cout << "Completed " << counter.load() << " tasks" << std::endl;
return 0;
}
Multi-threaded event loop backed by a pool of worker threads sharing one task queue.
适用场景
- 需要定时器功能同时又需要任务并行执行的场景
- 希望复用 MessageLoop API 但获得多线程吞吐量
- 传感器数据处理流水线,既有周期性采集又有并行计算需求
注意事项
- 任务回调中的共享状态必须由调用方自行保护(SpinLock、mutex 等)
- 不要在任务回调中调用 invoke_task() 并同步等待结果,否则可能因线程池耗尽而死锁
- MultiLoop 的名称自动编号为 MultiLoop_0、MultiLoop_1 等,可通过 set_name() 覆盖
MpmcQueue 无锁队列
算法原理
MpmcQueue<T> 是一个固定容量、无锁、缓存行对齐的 MPMC 环形缓冲区,基于 turn-counting(轮次计数) 算法实现。
核心思路:
- 环形缓冲区的每个槽位(Chunk)包含一个原子轮次计数器 turn
- 生产者通过原子递增 head_ 来声明一个槽位,然后等待 chunk.turn == turn(head) * 2(槽位为空)后写入
- 消费者通过原子递增 tail_ 来声明一个槽位,然后等待 chunk.turn == turn(tail) * 2 + 1(槽位有数据)后读取
- 写入完成后将 turn 设为 turn(head) * 2 + 1(标记为满)
- 读取完成后将 turn 设为 turn(tail) * 2 + 2(标记为空,下一轮可用)
等待策略:
- 前 32 次(kFirstSpinTimes)空转
- 超过 32 次后调用 Utils::yield_cpu()(x86 上是 PAUSE 指令,ARM 上是 WFE/YIELD)
64 字节对齐防伪共享
伪共享(False Sharing)是多核并发编程中的常见性能陷阱:当两个不同的原子变量恰好位于同一条缓存行(通常 64 字节)上时,一个核心的写操作会导致另一个核心的缓存行失效,即使它们访问的是不同的变量。
MpmcQueue 通过以下手段避免伪共享:
内存布局(64 字节对齐):
[ head_ (atomic, 64B 对齐) | padding... ] <-- 独占缓存行
[ chunk_*, capacity_ | cv_mtx_ ]
[ tail_ (atomic, 64B 对齐) | padding... ] <-- 独占缓存行
[ cv_not_empty_, cv_not_full_ ]
[ allocator_ ]
[ quit_flag_ (64B 对齐) | padding... ] <-- 独占缓存行
每个 Chunk 槽位也是 64 字节对齐的:
Chunk[0]: [ turn (atomic) | storage (T 的原始字节) | padding ] 64B 对齐
Chunk[1]: [ turn (atomic) | storage (T 的原始字节) | padding ] 64B 对齐
...
API 概览
阻塞式操作
q.push(42);
q.emplace(42);
int val;
q.pop(val);
Fixed-capacity, lock-free, cache-line-aligned MPMC ring buffer.
Definition mpmc_queue.h:109
非阻塞式操作
bool ok = q.try_push(42);
bool ok = q.try_emplace(42);
int val;
bool ok = q.try_pop(val);
条件变量通知模式
当与 kBlockStrategy 消息循环配合使用时,需要启用条件变量通知:
int val;
q.wait_not_empty();
q.wait_not_empty(std::chrono::milliseconds(100));
q.wait_not_full();
@ kConditionBehavior
Definition mpmc_queue.h:119
状态查询
size_t cap = q.capacity();
size_t sz = q.size();
size_t sz2 = q.size(true);
bool e = q.empty();
bool f = q.is_full();
优雅退出
Behavior 枚举
| 值 | push 时行为 | pop 时行为 |
| kNoBehavior | 无通知 | 无通知 |
| kConditionBehavior | 通知 cv_not_empty_ | 通知 cv_not_full_ |
容量规划建议
- 容量必须 >= 1,传入 0 会抛出 std::invalid_argument
- 每个槽位占用至少 64 字节(一个缓存行),加上 sizeof(T) 并向上对齐到 64 的倍数
- 经验公式:容量 = 预期突发峰值的 2-4 倍
完整示例:生产者-消费者
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
int main() {
std::atomic<int> sum{0};
constexpr int kProducers = 4;
constexpr int kConsumers = 4;
constexpr int kItemsPerProducer = 1000;
constexpr int kTotal = kProducers * kItemsPerProducer;
std::atomic<int> consumed_count{0};
std::vector<std::thread> consumers;
for (int c = 0; c < kConsumers; ++c) {
consumers.emplace_back([&]() {
while (true) {
int val = 0;
if (consumed_count.load() >= kTotal) {
break;
}
if (q.try_pop(val)) {
sum.fetch_add(val, std::memory_order_relaxed);
consumed_count.fetch_add(1);
} else {
std::this_thread::yield();
}
}
});
}
std::vector<std::thread> producers;
for (int p = 0; p < kProducers; ++p) {
producers.emplace_back([&, p]() {
int base = p * kItemsPerProducer;
for (int i = 0; i < kItemsPerProducer; ++i) {
q.push(base + i);
}
});
}
for (auto& t : producers) { t.join(); }
while (consumed_count.load() < kTotal) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
for (auto& t : consumers) { t.join(); }
std::cout << "Total sum: " << sum.load() << std::endl;
return 0;
}
Lock-free bounded multi-producer multi-consumer queue with optional blocking behaviour.
ObjectPool 对象池
概述
ObjectPool<T> 是一个线程安全的通用对象池,通过回收和重用对象来减少堆分配开销。它特别适用于需要频繁创建和销毁对象的热路径,例如消息缓冲区、序列化上下文等。
三种获取方式
| 方法 | 返回类型 | 自动归还 | 使用场景 |
| get() | unique_ptr<T, PoolDeleter> | 是 | 单一所有权,推荐默认使用 |
| get_shared() | shared_ptr<T> | 是 | 需要共享所有权 |
| borrow() | T*(裸指针) | 否 | 需要手动控制归还时机 |
对于 get() 和 get_shared(),当智能指针析构时,对象自动归还到池中而非被删除。borrow() 返回裸指针,必须由调用方手动调用 give_back() 归还。
ResetPolicy 枚举
| 策略 | 获取时重置 | 归还时重置 | 适用场景 |
| kPolicyNone | 否 | 否 | 不可变或无状态对象 |
| kPolicyRelease | 否 | 是 | 归还前清理(默认策略) |
| kPolicyAcquire | 是 | 否 | 使用前清理 |
| kPolicyBoth | 是 | 是 | 双侧清理 |
构造参数
auto pool = std::make_shared<vlink::ObjectPool<Buffer>>(
[]{ return std::make_unique<Buffer>(4096); },
4,
16,
[](Buffer& b){ b.clear(); },
);
@ kPolicyRelease
Invoke reset callback when object is returned to the pool.
Definition object_pool.h:134
注意:ObjectPool 必须通过 std::make_shared 创建,因为 PoolDeleter 持有 weak_ptr 引向池本身。
线程安全保证
所有公共方法通过内部互斥锁保护,可安全地从多个线程并发调用。但需要注意:
- 工厂回调在锁外执行,因此工厂回调本身必须是线程安全的
- 重置回调在锁外执行,同样需要线程安全
- 如果重置回调抛出异常,借出计数会正确递减,不会泄漏
统计信息
完整示例
#include <iostream>
#include <thread>
#include <vector>
struct Buffer {
std::vector<uint8_t> data;
explicit Buffer(size_t sz) : data(sz) {}
void clear() { std::fill(data.begin(), data.end(), 0); }
};
int main() {
auto pool = std::make_shared<vlink::ObjectPool<Buffer>>(
[]{ return std::make_unique<Buffer>(4096); },
4,
16,
[](Buffer& b){ b.clear(); },
);
{
auto buf = pool->get();
buf->data[0] = 0x42;
}
{
auto buf = pool->get_shared();
auto buf_copy = buf;
}
{
Buffer* raw = pool->borrow();
raw->data[0] = 0xFF;
pool->give_back(raw);
}
auto s = pool->stats();
std::cout << "Pool size: " << s.pool_size
<< ", Borrowed: " << s.borrowed
<< ", Total created: " << s.total_created << std::endl;
return 0;
}
Thread-safe generic object pool with configurable reset policy and RAII ownership.
池耗尽处理
当 max_size > 0 且所有对象都被借出时,get()、get_shared() 和 borrow() 会抛出 std::runtime_error。建议的处理策略:
- 设置合理的 max_size 上限
- 使用 try-catch 捕获耗尽异常并做降级处理
- 通过 stats() 监控池状态,在接近耗尽前发出告警
SpinLock 自旋锁
适用场景
SpinLock 适用于极短的临界区(几条 CPU 指令),在这种场景下 std::mutex 的上下文切换开销远大于等待时间本身。
典型场景:
- 原子地修改几个关联变量
- 更新统计计数器
- 保护简短的指针交换
不适合的场景:
- 临界区包含 I/O 操作
- 临界区执行时间不确定
- 低优先级线程可能被高优先级线程抢占导致优先级反转
自适应退避策略
SpinLock 使用指数退避策略来减少总线竞争:
第 1 轮: 自旋 1 次后 yield_cpu()
第 2 轮: 自旋 2 次后 yield_cpu()
第 3 轮: 自旋 4 次后 yield_cpu()
...
第 N 轮: 自旋 min(2^N, 1024) 次后 yield_cpu()
超过 50000 次总自旋: 记录错误日志并 sleep 10 微秒(安全阀机制)
yield_cpu() 在不同平台上映射为不同的指令:
| 平台 | 指令 | 作用 |
| x86/x64 | PAUSE | 降低流水线功耗,避免内存序违规 |
| ARM | WFE/YIELD | 让出执行到事件到达 |
| 其他 | sched_yield | 系统级让出 |
与 std::mutex 对比
| 指标 | SpinLock | std::mutex |
| 锁获取延迟 | 极低(纳秒级,无竞争时) | 中等(涉及系统调用) |
| 竞争时开销 | CPU 自旋浪费 | 线程挂起/唤醒 |
| 适合持有时长 | 极短(纳秒到微秒) | 任意 |
| 内存开销 | 64 字节(缓存行对齐) | 平台相关(通常 40-80 字节) |
| 递归锁定 | 死锁 | 可用 recursive_mutex |
| 优先级反转 | 可能发生 | 部分 OS 有优先级继承 |
API
}
{
}
RAII guard that acquires a SpinLock on construction and releases it on destruction.
Definition spin_lock.h:170
Adaptive, cache-line-aligned spin lock.
Definition spin_lock.h:95
void unlock() noexcept
Releases the lock.
Definition spin_lock.h:238
void lock() noexcept
Acquires the lock, spinning until successful.
Definition spin_lock.h:194
bool try_lock() noexcept
Attempts to acquire the lock without blocking.
Definition spin_lock.h:230
SpinLock 满足 C++ Lockable 具名要求,也可以与 std::lock_guard 配合使用:
{
std::lock_guard<vlink::SpinLock> guard(lock);
}
完整示例
#include <thread>
#include <vector>
#include <iostream>
int main() {
int counter = 0;
constexpr int kThreads = 8;
constexpr int kOps = 10000;
std::vector<std::thread> workers;
for (int i = 0; i < kThreads; ++i) {
workers.emplace_back([&]() {
for (int j = 0; j < kOps; ++j) {
++counter;
}
});
}
for (auto& w : workers) {
w.join();
}
std::cout << "Counter: " << counter << std::endl;
return 0;
}
Adaptive, cache-line-aligned spin lock and RAII guard.
Semaphore 信号量
概述
Semaphore 是一个进程内计数信号量,提供经典的 P/V(acquire/release)语义。内部基于 std::mutex 和条件变量实现,条件变量使用 CLOCK_MONOTONIC 以避免 Linux 上 NTP 时钟跳变导致的问题。
API
bool ok = sem.acquire(1);
bool ok = sem.acquire(1, 100);
bool ok = sem.acquire(1, Semaphore::kInfinite);
sem.release(1);
sem.release(3);
sem.reset();
sem.reset(true);
size_t count = sem.get_count();
In-process counting semaphore with optional acquire timeout.
Definition semaphore.h:82
生产者-消费者模式
#include <thread>
#include <queue>
#include <mutex>
#include <iostream>
int main() {
std::queue<int> buffer;
std::mutex mtx;
std::thread producer([&]() {
for (int i = 0; i < 10; ++i) {
{
std::lock_guard<std::mutex> lock(mtx);
buffer.push(i);
}
sem.release();
}
});
std::thread consumer([&]() {
for (int i = 0; i < 10; ++i) {
sem.acquire();
int val;
{
std::lock_guard<std::mutex> lock(mtx);
val = buffer.front();
buffer.pop();
}
std::cout << "Consumed: " << val << std::endl;
}
});
producer.join();
consumer.join();
return 0;
}
In-process counting semaphore with optional timeout.
资源池限流
void access_resource() {
if (pool_sem.acquire(1, 5000)) {
pool_sem.release();
} else {
}
}
优雅关闭
std::thread worker([&]() {
while (sem.acquire(1)) {
}
});
sem.reset(true);
worker.join();
注意事项
- acquire() 的超时使用毫秒为单位,kInfinite(-1)表示无限等待
- get_count() 返回的是快照值,在并发环境下仅供调试参考
- 这是进程内信号量;如需跨进程同步,请使用 SysSemaphore
- reset(true) 是破坏性操作,仅在受控关闭时使用
并发原语选型决策树
需要任务调度?
|
+-- 需要串行执行 ---------> MessageLoop
|
+-- 需要并行执行
|
+-- 需要定时器 -------> MultiLoop
|
+-- 纯并行计算 -------> ThreadPool
需要线程间数据传输?
|
+-- 固定容量 + 高吞吐 ----> MpmcQueue
|
+-- 需要背压控制 ----------> MpmcQueue + wait_not_full/wait_not_empty
|
+-- 对象重用 + 减少分配 ---> ObjectPool
需要互斥保护?
|
+-- 极短临界区(纳秒级)---> SpinLock
|
+-- 一般临界区 ------------> std::mutex
|
+-- 需要条件等待 ----------> vlink::ConditionVariable(CLOCK_MONOTONIC,避免 NTP 跳变)
需要线程间信号通知?
|
+-- 简单信号 --------------> Semaphore
|
+-- 需要计数限流 ----------> Semaphore(初始计数 = 并发上限)
避免伪共享
伪共享是并发性能的隐形杀手。VLink 的 MpmcQueue 和 SpinLock 已经通过 64 字节对齐避免了内部伪共享。在编写自己的并发数据结构时,请遵循以下原则:
- 不同线程频繁访问的原子变量应当分别对齐到独立的缓存行
struct Bad {
std::atomic<int> counter_a;
std::atomic<int> counter_b;
};
struct Good {
alignas(64) std::atomic<int> counter_a;
alignas(64) std::atomic<int> counter_b;
};
- 数组中的元素如果被不同线程并发访问,每个元素应对齐到缓存行
- 只读数据和读写数据分离:将不变的配置字段与频繁更新的状态字段放在不同的缓存行上
组合使用示例
以下示例展示如何组合使用 MultiLoop、MpmcQueue 和 ObjectPool 构建一个高性能的消息处理管道:
#include <iostream>
#include <memory>
struct Message {
int id{0};
std::string payload;
void reset() { id = 0; payload.clear(); }
};
int main() {
auto msg_pool = std::make_shared<vlink::ObjectPool<Message>>(
[]{ return std::make_unique<Message>(); },
8,
64,
[](Message& m){ m.reset(); },
);
for (int i = 0; i < 100; ++i) {
auto msg = msg_pool->get();
msg->id = i;
msg->payload = "data_" + std::to_string(i);
});
}
auto s = msg_pool->stats();
std::cout << "Pool stats - idle: " << s.pool_size
<< ", total created: " << s.total_created << std::endl;
return 0;
}
11.9 IPC 原语
VLink 在 vlink::base 层提供了两个跨进程 IPC 原语类:
这两个类直接封装操作系统的 IPC 机制,为上层模块和用户代码提供最底层的进程间同步与数据共享能力。它们不依赖任何第三方库,仅使用 POSIX 或 Win32 原生 API。
SysSemaphore 系统信号量
基本概念
SysSemaphore 是一个命名的、跨进程的计数信号量。多个进程通过相同的名称访问同一个内核信号量对象,实现 P/V 操作(即 acquire/release)。
核心特点:
- **命名语义**:通过操作系统命名空间标识,任何知道名称的进程都可以打开同一个信号量。
- **计数信号量**:内部维护一个非负整数计数器。release() 增加计数,acquire() 减少计数;当计数为 0 时 acquire() 阻塞调用者。
- **RAII 管理**:析构函数自动调用 detach() 关闭句柄。
生命周期
构造 --> attach(name) --> acquire()/release() --> detach(force) --> 析构
- **构造**:SysSemaphore(count) 创建对象,count 为初始计数(默认 0)。此时尚未关联任何 OS 信号量。
- **attach(name)**:创建或打开一个命名信号量。如果该名称的信号量在系统中不存在,则以指定初始计数创建;如果已存在,则直接打开(忽略构造时的初始计数)。
- **acquire(n, timeout_ms)**:P 操作,将计数减少 n。如果计数不足则阻塞,直到超时或其他线程/进程释放了足够的许可。
- **release(n)**:V 操作,将计数增加 n,唤醒最多 n 个阻塞在 acquire() 上的等待者。
- **detach(force)**:关闭句柄。若 force=true 则同时从 OS 命名空间中删除(sem_unlink);若 force=false 则仅关闭本进程的句柄。
- **析构**:自动调用 detach(false)(仅关闭句柄,不删除)。
API 参考
class SysSemaphore final {
public:
static constexpr int kInfinite{-1};
explicit SysSemaphore(size_t count = 0);
~SysSemaphore();
bool attach(const std::string& name);
bool detach(bool force = true);
bool acquire(size_t n = 1, int timeout_ms = kInfinite);
void release(size_t n = 1);
bool is_attached() const;
size_t get_count() const;
};
| 方法 | 返回值 | 说明 |
| attach | bool | 成功返回 true;重复 attach 会返回 false 并打印错误日志 |
| detach | bool | 未 attach 时返回 false |
| acquire | bool | 超时或错误返回 false;timeout_ms=0 为非阻塞尝试 |
| release | void | n=0 时不做任何操作 |
| is_attached | bool | 查询当前是否已关联 OS 信号量 |
| get_count | size_t | 获取当前计数快照(仅用于诊断,值可能随即改变) |
POSIX 命名规则
在 POSIX 系统(Linux、macOS)上,命名信号量的名称必须以 / 开头,例如 /vlink_ready、/my_sem_01。名称中不能包含额外的 /。名称长度受 NAME_MAX 限制(通常 255 字节)。
在 Windows 上,信号量名称可以是任意非空字符串。
超时机制
| timeout_ms 值 | 行为 | 底层 API (POSIX) |
| kInfinite (-1) | 无限等待,直到获取到许可 | sem_wait() |
| 0 | 非阻塞尝试,立即返回 | sem_timedwait(now) |
| > 0 | 最多等待指定毫秒数 | sem_timedwait() |
SysSharemem 系统共享内存
基本概念
SysSharemem 封装了操作系统命名共享内存区域。一个进程通过 create() 创建并映射一块共享内存,其他进程通过相同名称调用 attach() 将该内存映射到自己的地址空间,从而实现零拷贝的数据共享。
核心特点:
- **命名语义**:与 SysSemaphore 类似,通过 OS 命名空间标识共享内存对象。
- **显式创建/附加分离**:create() 分配并映射新区域,attach() 仅映射已存在的区域。
- **访问模式控制**:支持只读 (kReadOnly) 和读写 (kReadWrite) 两种映射模式。
- **RAII 管理**:析构函数自动调用 detach(false) 取消映射(但不删除 OS 对象)。
生命周期
创建者: 构造 --> create(name, size) --> data() 读写 --> detach(true) 删除
附加者: 构造 --> attach(name) --> data() 读写 --> detach(false) 仅取消映射
API 参考
class SysSharemem final {
public:
enum Mode : uint8_t {
kReadOnly = 0,
kReadWrite = 1
};
SysSharemem();
~SysSharemem();
bool create(const std::string& name, size_t size, Mode mode = kReadWrite);
bool attach(const std::string& name, Mode mode = kReadWrite);
bool detach(bool force = true);
bool is_attached() const;
void* data();
const void* data() const;
size_t size() const;
};
| 方法 | 返回值 | 说明 |
| create | bool | 同名已存在时返回 false(O_EXCL 语义) |
| attach | bool | 对象不存在时返回 false |
| detach | bool | 未 attach 时返回 false |
| is_attached | bool | 数据指针、大小、句柄、名称均有效时返回 true |
| data() | void* | 未 attach 时返回 nullptr |
| data() const | const void* | 只读访问,未 attach 时返回 nullptr |
| size() | size_t | 返回映射区域大小(字节),未 attach 时返回 0 |
访问模式
| Mode | POSIX mmap 标志 | Windows 标志 | 说明 |
| kReadOnly | PROT_READ | FILE_MAP_READ | 只读映射 |
| kReadWrite | PROT_READ | PROT_WRITE | FILE_MAP_ALL_ACCESS | 读写映射(默认) |
kReadOnly 模式下,通过 data() 返回的指针写入数据会触发段错误(SIGSEGV / Access Violation)。
跨进程同步模式
SysSemaphore 和 SysSharemem 配合使用是实现跨进程数据交换的经典模式:
创建者进程 消费者进程
| |
|-- SysSharemem::create("/data", 4096) |
|-- SysSemaphore(0).attach("/notify") |
| |
|-- 写入数据到 shm.data() |-- SysSharemem::attach("/data")
|-- sem.release() ---- 信号 ----> |-- SysSemaphore(0).attach("/notify")
| |-- sem.acquire() // 收到信号
| |-- 读取 shm.data()
| |
与 VLink 传输后端的关系
| 层级 | 组件 | 说明 |
| 用户 API 层 | Publisher / Subscriber / Client 等 | 面向业务的发布/订阅/RPC 接口 |
| 传输后端层 | shm://(Iceoryx)、dds://(FastDDS) 等 | 封装具体传输协议,用户通过 URL 选择 |
| OS IPC 原语层 | SysSemaphore、SysSharemem | 直接封装操作系统 API |
平台 API 映射表
SysSemaphore 平台 API 映射
| 操作 | Linux (POSIX) | macOS (GCD) | Windows (Win32) |
| 创建/打开 | sem_open() | dispatch_semaphore_create() | CreateSemaphore() |
| 关闭句柄 | sem_close() | 释放 dispatch 对象 | CloseHandle() |
| 删除(unlink) | sem_unlink() | 不支持(GCD 信号量无命名空间) | 不支持(句柄关闭即释放) |
| P 操作 | sem_wait() | dispatch_semaphore_wait() | WaitForSingleObjectEx() |
| P 超时 | sem_timedwait() | dispatch_semaphore_wait(timeout) | WaitForSingleObjectEx(ms) |
| V 操作 | sem_post() | dispatch_semaphore_signal() | ReleaseSemaphore() |
| 获取计数 | sem_getvalue() | 不支持 | ReleaseSemaphore(0, &cnt) |
| 命名规则 | 必须以 / 开头 | 名称被忽略(非命名信号量) | 任意非空字符串 |
注意事项:
- **macOS**:使用 GCD 的 dispatch_semaphore,不支持命名语义,无法真正跨进程使用。get_count() 也不可用。
- **Windows**:detach(force) 中的 force 参数被忽略,Win32 信号量在所有句柄关闭后自动销毁。
- **Linux**:命名信号量在 /dev/shm/ 目录下以 sem. 前缀的文件形式存在。
SysSharemem 平台 API 映射
| 操作 | Linux (POSIX) | Windows (Win32) | Android |
| 创建 | shm_open() + ftruncate() | CreateFileMapping() | 不支持 |
| 打开 | shm_open() | OpenFileMapping() | 不支持 |
| 映射 | mmap(MAP_SHARED) | MapViewOfFile() | 不支持 |
| 取消映射 | munmap() | UnmapViewOfFile() | 不支持 |
| 删除(unlink) | shm_unlink() | CloseHandle() | 不支持 |
| 获取大小 | fstat() | VirtualQuery() | 不支持 |
| 防止缩小 | fcntl(F_ADD_SEALS) | 不适用 | 不支持 |
| 命名规则 | 必须以 / 开头 | 任意非空字符串 | 不支持 |
| 权限 | 0600 (owner rw) / 0400 (r) | 通过映射标志控制 | 不支持 |
注意事项:
- **Android**:Bionic libc 不支持 shm_open(),create() 和 attach() 均返回 false。需使用 ashmem 或 memfd_create 替代。
- **QNX**:detach() 时通过 fstat() 的 st_nlink 判断附加计数,最后一个附加者 detach 时自动 unlink。
完整示例
生产者进程
#include <cstdio>
#include <cstring>
struct SharedMessage {
uint32_t seq;
uint32_t length;
char payload[256];
};
int main() {
if (!shm.
create(
"/vlink_demo_shm",
sizeof(SharedMessage))) {
std::fprintf(stderr, "Failed to create shared memory\n");
return 1;
}
if (!sem.attach("/vlink_demo_sem")) {
std::fprintf(stderr, "Failed to create semaphore\n");
return 1;
}
auto* msg =
static_cast<SharedMessage*
>(shm.
data());
msg->seq = 1;
const char* text = "Hello from producer!";
msg->length = static_cast<uint32_t>(std::strlen(text));
std::memcpy(msg->payload, text, msg->length + 1);
std::printf("Producer: wrote message seq=%u\n", msg->seq);
sem.release();
sem.detach(true);
return 0;
}
Named cross-process counting semaphore.
Definition sys_semaphore.h:83
Named cross-process shared memory backed by the OS IPC layer.
Definition sys_sharemem.h:95
bool create(const std::string &name, size_t size, Mode mode=kReadWrite)
Creates a new named shared memory region of the given size and maps it.
bool detach(bool force=true)
Unmaps the shared memory region and optionally unlinks the OS object.
void * data()
Returns a writable pointer to the beginning of the shared memory region.
Named, cross-process counting semaphore backed by the OS IPC layer.
Named cross-process shared memory region.
消费者进程
#include <cstdio>
int main() {
std::fprintf(stderr, "Failed to attach shared memory\n");
return 1;
}
if (!sem.
attach(
"/vlink_demo_sem")) {
std::fprintf(stderr, "Failed to attach semaphore\n");
return 1;
}
std::printf("Consumer: waiting for data...\n");
std::fprintf(stderr, "Consumer: timeout waiting for data\n");
return 1;
}
const auto* msg =
static_cast<const SharedMessage*
>(shm.
data());
std::printf("Consumer: received message seq=%u, payload=\"%s\"\n",
msg->seq, msg->payload);
return 0;
}
bool detach(bool force=true)
Closes the semaphore handle and optionally removes it from the OS namespace.
bool attach(const std::string &name)
Creates or opens a named semaphore with the given name.
bool acquire(size_t n=1, int timeout_ms=kInfinite)
Decrements the semaphore counter by n, blocking if necessary.
@ kReadOnly
Read-only mapping (PROT_READ).
Definition sys_sharemem.h:101
bool attach(const std::string &name, Mode mode=kReadWrite)
Attaches to an existing named shared memory region.
IPC 原语注意事项
- **资源泄漏**:POSIX 命名信号量和共享内存在进程崩溃后不会自动从命名空间中删除。应在程序启动时检查并清理遗留对象。
- **析构行为**:两个类的析构函数均调用 detach(false),仅关闭句柄不删除 OS 对象。如需删除,必须手动调用 detach(true)。
- **并发访问**:共享内存本身不提供同步保护,必须配合 SysSemaphore 或进程间互斥锁使用。
- **未初始化内存**:SysSharemem::create() 分配的区域不会自动清零,使用前应 std::memset(shm.data(), 0, shm.size())。
- **权限控制**:POSIX 下 create() 使用 0600 权限,不同用户需调整权限。
- **大小限制**:受 /dev/shm tmpfs 大小限制。大型数据传输建议使用 VLink 的 shm:// 传输后端。
- **不可拷贝**:SysSemaphore 和 SysSharemem 均不可拷贝,需通过指针或引用传递。
11.10 任务调度
Schedule – 任务调度包装器
概述
vlink::Schedule 是一个非构造工具结构体,通过 MessageLoop::exec_task() 使用。 它将回调包装在 Config 配置中,支持**延迟、优先级、调度超时和执行超时**, 并返回一个 RAII 句柄用于链式注册延续回调。
Config 字段
| 字段 | 含义 |
| delay_ms | 任务发布前的延迟(毫秒) |
| priority | 调度优先级(用于 kPriorityType 循环) |
| schedule_timeout_ms | 任务未在此时间内启动则触发超时 |
| execution_timeout_ms | 任务执行超过此时间则触发超时 |
使用示例
[] { expensive_op(); })
.on_execution_timeout([] {
VLOG_W(
"task took too long!"); })
.on_catch([](std::exception& e) {
VLOG_E(
"exception: ", e.what()); });
[]() -> bool { return try_connect(); })
.on_then([]() -> bool {
start_session();
return true;
})
.on_then([]() -> bool {
subscribe_topics();
return true;
})
.on_else([] { retry_later(); })
.on_schedule_timeout([] {
VLOG_W(
"task not scheduled in time"); });
GraphTask – 有向无环图任务调度
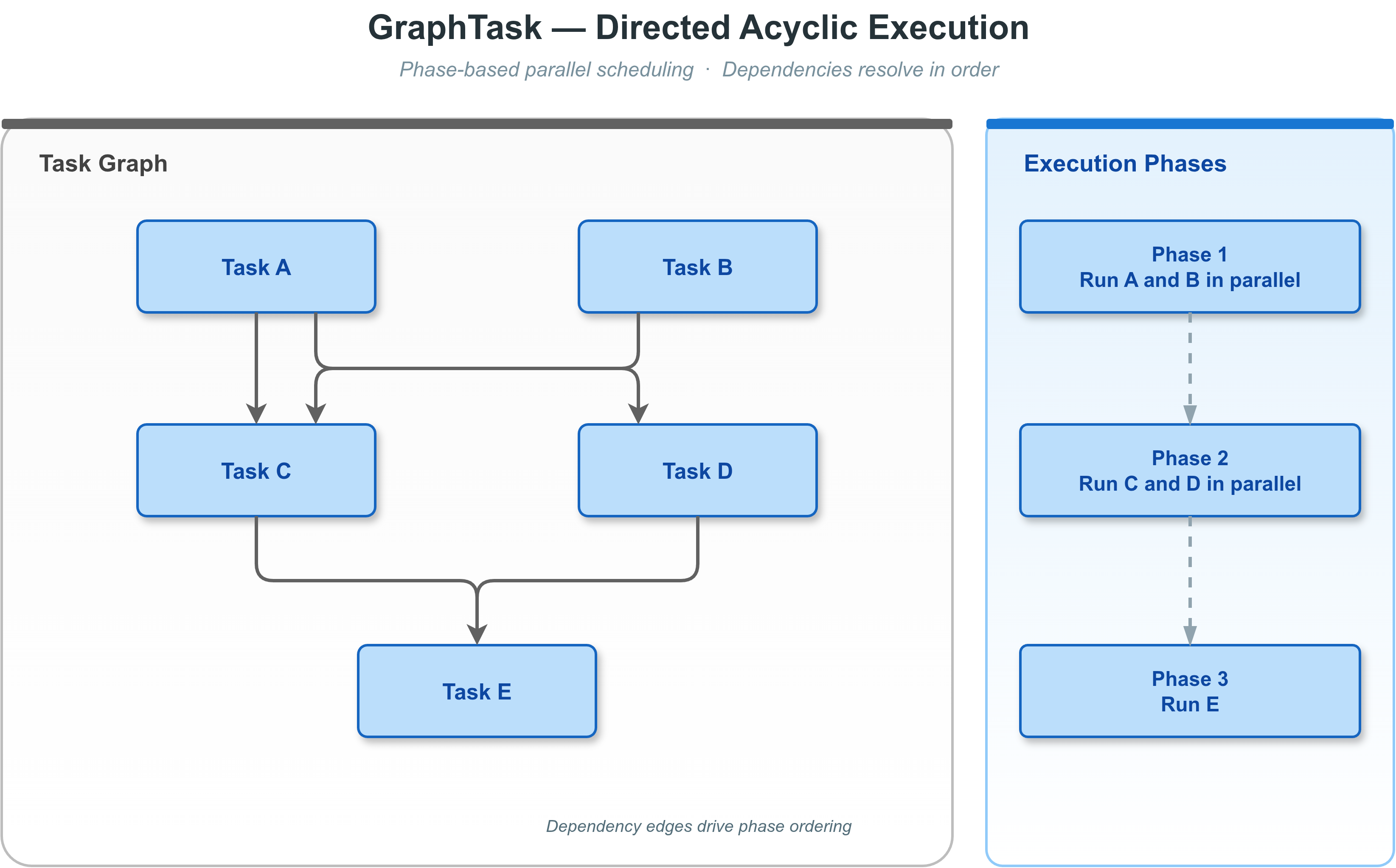
DAG 任务调度示例
概述
vlink::GraphTask 实现 DAG(有向无环图)任务调度。 每个任务节点通过 precede() / succeed() 声明依赖关系, 然后调用 execute() 提交到任意兼容引擎(MessageLoop、MultiLoop、ThreadPool)。
任务类型
| 工厂方法 | 回调签名 | 用途 |
| create(callback) | void() | 普通工作任务 |
| create_condition(cb) | int() | 条件分支(返回值选择分支) |
依赖声明语法
GraphTask 重载了 -- > 和 -- < 运算符用于声明依赖关系:
| 表达式 | 等价调用 | 含义 |
| A -- > B | A->succeed(B) | B 是 A 的前驱(B 先执行) |
| A -- < B | A->precede(B) | A 是 B 的前驱(A 先执行) |
也可以使用 precede() / succeed() 方法直接声明依赖。
执行策略
| 策略 | 含义 |
| kPolicyOnce | 每次 execute() 调用最多运行一次(默认) |
| kPolicyMultiple | 单次 execute() 可运行多次 |
| kPolicyWaitAll | 等待所有前驱完成后才运行 |
使用示例
save -- > proc -- > load;
clean -- > proc;
assert(!save->has_cycle());
save->register_status_callback([](const std::string& name,
VLOG_D(
"task ", name,
" status=", (
int)s);
});
save->execute(&engine);
[]() -> int {
return is_valid() ? 0 : 1;
}, 2);
branch_a -- > check;
branch_b -- > check;
branch_a->execute(&engine);
std::string dot = save->export_to_dot();
Status
Execution state of the task within a single execute() pass.
Definition graph_task.h:112
static std::shared_ptr< GraphTask > create(Callback &&callback, int condition_number=0)
Creates a regular (void) task node.
static std::shared_ptr< GraphTask > create_condition(ConditionCallback &&callback, int condition_number=0)
Creates a condition task that returns a branch index.
DAG-based task graph with condition branching, cycle detection, and DOT export.
#define VLOG_D(...)
Definition logger.h:848
11.11 性能分析
VLink 内置轻量级性能分析工具,用于量化节点和通信操作的 CPU 利用率, 同时提供高性能日志格式化流。
CpuProfiler CPU 分析器
vlink::CpuProfiler 通过 begin() / end() 配对调用,测量 CPU 活跃时间 占总墙钟时间(wall-clock time)的百分比。
工作原理
内部维护两个 ElapsedTimer:
| 计时器 | 时钟类型 | 用途 |
| cpu_active_timer_ | kCpuActiveTime | 每次 begin/end 区间的 CPU 活跃时间 |
| cpu_timestamp_timer_ | kCpuTimestamp | 从首次 begin 到当前的总墙钟时间 |
利用率计算公式:
utilisation (%) = (sum of active intervals / total elapsed time) * 100
全局开关
CpuProfiler 的激活受环境变量 VLINK_PROFILER_ENABLE 控制。 该值在首次调用 is_global_enabled() 时读取并缓存,整个进程生命周期内不再变更。
# 启用性能分析
export VLINK_PROFILER_ENABLE=1
# 禁用(默认)
export VLINK_PROFILER_ENABLE=0
API 说明
| 方法 | 说明 |
| CpuProfiler() | 构造,所有累加器初始化为零 |
| begin() | 标记活跃区间开始,重置活跃计时器;首次调用同时启动墙钟计时器 |
| end() | 标记活跃区间结束,累加本次活跃时间到 total_active_ |
| get() | 返回当前 CPU 利用率百分比 [0.0, 100.0],不重置任何状态 |
| restart() | 返回当前利用率并重置所有累加器,之后 get() 返回 0.0 |
| is_global_enabled() (static) | 返回环境变量 VLINK_PROFILER_ENABLE 是否为 "1" |
注意事项:
- begin() 和 end() 内部通过 SpinLock 保护,可从任意线程调用
- 允许连续多次 begin() 而不调用 end()(每次 begin 重置活跃计时器基线)
- end() 在未调用 begin() 的情况下安全执行,负值会被忽略
- 实例不可拷贝、不可赋值
基本用法
for (auto& item : work_items) {
process(item);
}
double pct = profiler.
get();
double reset_pct = profiler.
restart();
Tracks CPU active time as a percentage of total elapsed wall-clock time.
Definition cpu_profiler.h:94
void begin() noexcept
Marks the start of an active CPU work section.
double get() const noexcept
Returns the current CPU utilisation ratio as a percentage.
double restart() noexcept
Returns the current utilisation and resets all accumulators to zero.
void end() noexcept
Marks the end of an active CPU work section and accumulates the elapsed time.
Per-instance CPU utilisation profiler gated by a global environment variable.
CpuProfilerGuard RAII 守护
vlink::CpuProfilerGuard 是一个轻量 RAII 包装器: 构造时调用 profiler->begin(),析构时调用 profiler->end(), 保证即使发生异常也能正确关闭活跃区间。
| 方法 | 说明 |
| CpuProfilerGuard(CpuProfiler* profiler) | 构造并调用 begin();profiler 为 nullptr 时为空操作 |
| ~CpuProfilerGuard() | 析构并调用 end();profiler 为 nullptr 时为空操作 |
注意事项:
- 传入 nullptr 是安全的,构造和析构均为空操作
- 不可拷贝、不可移动,仅用作栈上局部变量
- 在热路径中建议先检查 is_global_enabled() 以跳过构造开销
void process_frame() {
}
void hot_path_callback(const SensorData& data) {
process(data);
}
RAII scope guard that brackets a CpuProfiler active interval.
Definition cpu_profiler_guard.h:67
static bool is_global_enabled() noexcept
Returns whether CPU profiling is globally enabled via environment variable.
RAII guard that automatically calls CpuProfiler::begin() and CpuProfiler::end().
与 Node 的集成
VLink 的所有通信节点(Publisher、Subscriber、Client、Server、Getter、Setter) 内部持有一个可选的 CpuProfiler 实例。当全局性能分析开启时,每次 publish、 receive、request、respond 等操作都会自动通过 CpuProfilerGuard 记录 CPU 活跃时间。
通过 Node::get_cpu_usage() 可获取该节点从创建至今的 CPU 利用率百分比:
double cpu = sub.get_cpu_usage();
if (cpu >= 0) {
VLOG_I(
"subscriber CPU usage: ", cpu,
"%");
} else {
VLOG_W(
"profiler not available (VLINK_PROFILER_ENABLE not set)");
}
| 返回值 | 含义 |
| [0.0, 100.0] | 正常的 CPU 利用率百分比 |
| -1.0 | 性能分析器未挂载(未启用 VLINK_PROFILER_ENABLE) |
启用步骤:
# 1. 设置环境变量
export VLINK_PROFILER_ENABLE=1
# 2. 启动应用
./my_vlink_app
无需修改代码,通信节点会自动开始采集 CPU 利用率数据。
FastStream 高性能流
vlink::FastStream 是 VLink Logger 内部使用的高性能输出流,继承自 std::ostream, 支持所有标准流格式化操作符,同时提供零拷贝的缓冲区交付机制。
设计要点
- 内部由一个 StringBuf(继承自 std::streambuf)驱动,数据存储在 std::string 中
- 默认初始容量 256 字节,自动增长,增长步幅上限为 8 KiB(kMaxExpandSize)
- take_view() 返回内部缓冲区的 std::string_view,实现零拷贝交付
- write_raw() 绕过 std::ostream 格式化,直接写入原始字节,适合预格式化字符串
- 非线程安全,Logger 内部采用 thread_local 实例
API 说明
| 方法 | 说明 |
| FastStream() | 构造,初始容量 256 字节 |
| reset() | 清空缓冲区内容并重置流状态,不释放内存 |
| take_view() | 返回缓冲区内容的 string_view,有效期至下次写入 |
| append_to(std::string& target) | 将缓冲区内容追加到外部字符串,不重置缓冲区 |
| size() | 返回当前缓冲区已写入字节数 |
| capacity() | 返回当前缓冲区分配容量(字节) |
| shrink_to_fit() | 释放多余容量,最小保留 64 字节(kMinCapacity) |
| write_raw(const char* data, size_t len) | 直接写入原始字节,绕过 ostream 格式化,返回 *this |
| operator<< | 兼容所有 std::ostream 格式化操作符 |
缓冲区管理
| 常量 | 值 | 说明 |
| kDefaultCapacity | 256 | 构造时的初始缓冲区容量(字节) |
| kMinCapacity | 64 | shrink_to_fit 后的最小容量 |
| kMaxExpandSize | 8192 | 单次增长的上限步幅(8 KiB) |
用法示例
stream << "sensor_id=" << 42 << " value=" << 3.14;
write_to_sink(view);
const char* header = "[INFO] ";
stream << "message content";
High-performance std::ostream with an embedded resizable string buffer.
Definition fast_stream.h:78
std::string_view take_view() noexcept
Returns a std::string_view of the current buffer contents.
void reset() noexcept
Clears all buffered content and resets the stream error state.
FastStream & write_raw(const char *data, size_t len) noexcept
Writes raw bytes directly into the buffer, bypassing std::ostream formatting.
void shrink_to_fit() noexcept
Releases any excess capacity allocated by the internal buffer.
A high-performance std::ostream backed by a resizable std::string buffer.
完整代码示例
手动性能分析
int main() {
VLOG_W(
"profiler is disabled, set VLINK_PROFILER_ENABLE=1 to enable");
}
heavy_computation();
VLOG_I(
"CPU usage after computation: ", profiler.
get(),
"%");
{
another_computation();
}
VLOG_I(
"CPU usage after both: ", profiler.
get(),
"%");
double final_usage = profiler.
restart();
VLOG_I(
"final usage: ", final_usage,
"%");
VLOG_I(
"after restart: ", profiler.
get(),
"%");
return 0;
}
11.12 工具类
Format – 轻量格式化器
概述
vlink::format 是一个仅头文件的轻量 {} 占位符格式化器,专为日志热路径设计。 所有格式化写入栈分配缓冲区或用户提供的输出迭代器,**不触及堆**。
支持的类型
| C++ 类型 | 输出示例 |
| int / short / signed char | 42 |
| unsigned / unsigned short / ... | 42 |
| long / long long | 123456789 |
| bool | true / false |
| char | A |
| float / double | 3.14 |
| const char* / std::string / std::string_view | hello |
| 任意指针 T* | 0x7ffe1234 |
| 任意枚举 | 底层整数值 |
| 其他自定义类型 | 编译期 static_assert 报错 |
占位符语法:
- {} – 按顺序消耗参数
- {0}, {1} – 显式位置索引
- {{ / }} – 字面量花括号
使用示例
char buf[128];
buf, sizeof(buf) - 1, "x={} y={} name={}", 3, 4.5, "world");
buf[result.size] = '\0';
if (result.truncated) {
}
char arr[64];
std::string out;
Utils – 系统工具函数
概述
vlink::Utils 命名空间提供跨平台的系统级工具函数,覆盖进程、线程、网络、信号等方面。 所有函数均为 noexcept,错误以空字符串、false 或哨兵值(如 pid == -1)表示。
进程与应用信息
VLINK_EXPORT std::string get_app_path() noexcept
Returns the absolute path of the running executable.
VLINK_EXPORT std::string get_tmp_dir() noexcept
Returns the platform-specific temporary directory path.
VLINK_EXPORT std::string get_host_name() noexcept
Returns the host name of the current machine.
VLINK_EXPORT std::string get_app_name() noexcept
Returns the file name of the running executable (without directory prefix).
VLINK_EXPORT std::string get_app_dir() noexcept
Returns the directory containing the running executable.
VLINK_EXPORT int32_t get_pid() noexcept
Returns the process ID of the current process.
VLINK_EXPORT std::string get_machine_id() noexcept
Returns a unique identifier for the current machine.
Platform-agnostic system utilities for process, thread, network and signal management.
环境变量
VLINK_EXPORT std::string get_env(const std::string &key, const std::string &default_value="") noexcept
Reads the value of an environment variable.
VLINK_EXPORT bool set_env(const std::string &key, const std::string &value, bool force=true) noexcept
Sets or updates an environment variable.
VLINK_EXPORT bool unset_env(const std::string &key) noexcept
Removes an environment variable.
线程管理
VLINK_EXPORT bool set_thread_stick(uint32_t core_mask, std::thread *thread=nullptr) noexcept
Pins a thread to a set of CPU cores specified by a bitmask.
VLINK_EXPORT void yield_cpu() noexcept
Emits a CPU pause/yield hint to reduce bus contention in busy-wait loops.
Definition utils.h:412
VLINK_EXPORT uint64_t get_native_thread_id() noexcept
Returns the native OS thread identifier of the calling thread.
VLINK_EXPORT bool set_thread_priority(int priority_level, int policy=-1, std::thread *thread=nullptr) noexcept
Sets the scheduling policy and priority of a thread.
信号处理
[](int sig) {
VLOG_I(
"terminating, signal=", sig);
app.shutdown();
},
false,
false);
});
static void flush() noexcept
Flushes all buffered log messages to the active sinks.
VLINK_EXPORT void register_crash_signal(std::function< void(int)> &&callback) noexcept
Registers a callback for crash signals (SIGSEGV, SIGABRT, SIGFPE, SIGBUS, etc.).
VLINK_EXPORT void register_terminate_signal(std::function< void(int)> &&callback, bool is_async=false, bool pass_through=false) noexcept
Registers a callback for graceful termination signals (SIGTERM, SIGINT, etc.).
网络工具
VLINK_EXPORT std::string get_interface_name_by_ipv4(const std::string &ipv4) noexcept
Returns the network interface name that owns a given IPv4 address.
VLINK_EXPORT std::vector< std::string > get_dds_default_address(bool filter_available=false, int max_count=5) noexcept
Returns suitable IPv4 addresses for use as DDS participant unicast locators.
VLINK_EXPORT std::vector< std::string > get_all_ipv6_address(bool filter_available=false) noexcept
Returns all IPv6 addresses assigned to local network interfaces.
VLINK_EXPORT std::vector< std::string > get_all_ipv4_address(bool filter_available=false) noexcept
Returns all IPv4 addresses assigned to local network interfaces.
其他工具
VLOG_F(
"another instance is already running");
}
VLINK_EXPORT double get_memory_usage() noexcept
Returns the resident set size (RSS) of the process as a percentage of total RAM.
VLINK_EXPORT int32_t get_timezone_diff() noexcept
Returns the local timezone offset from UTC in seconds.
VLINK_EXPORT bool check_singleton(const std::string &program_name="") noexcept
Checks that only one instance of the process is running (singleton guard).
VLINK_EXPORT bool wait_for_device(const std::string &path, int timeout_ms, int poll_ms=50) noexcept
Blocks until a file-system path appears or the timeout elapses.
VLINK_EXPORT void try_release_sys_memory() noexcept
Hints to the OS that any unreferenced cached memory pages can be released.
VLINK_EXPORT double get_cpu_usage() noexcept
Returns the current CPU usage of the process as a percentage.